


สำหรับบทความนี้แอดจะพามาเริ่มต้นรู้จักกับคำว่า “Computer Vision” ในยุคนี้ที่เทคโนโลยีบูม ๆ เอไอปัง ๆ ทุกอย่างมันอยู่รอบตัวไปหมด มีการเอา Computer Vision มาใช้ในชีวิตประจำวันเต็มไปหมดไม่ว่าจะเป็นระบบตรวจจับป้ายทะเบียน หรือ AI ที่อยู่ในระบบขับรถอัตโนมัติ หรือแม้แต่ AI ในการคัดแยกภาพต่างก็ต้องเข้าใจเรื่องของ Computer Vision กันทั้งนั้น
Computer Vision คืออะไร?
Computer Vision หรือแปลเป็นไทยว่า “การมองเห็นด้วยคอมพิวเตอร์” มันคือการที่ คอมพิวเตอร์หรือมือถือของเรามองเห็นภาพหรือเข้าใจภาพได้ ถ้าเทียบกับเราที่เป็นคนเวลาเห็นภาพถ่ายรูปเพื่อน เราก็จะรู้ทันทีว่านั่นคือใคร กำลังทำอะไร และอยู่ที่ไหน
แต่คอมพิวเตอร์ไม่ได้มี “ตา” เหมือนเรา แต่เราสามารถใช้ “กล้อง” เป็นตาให้คอมพิวเตอร์สามารถมองเห็นได้
เมื่อกล้องถ่ายภาพได้แล้ว

คอมพิวเตอร์จะมองภาพนั้นเป็นตัวเลข จำนวนมากๆ
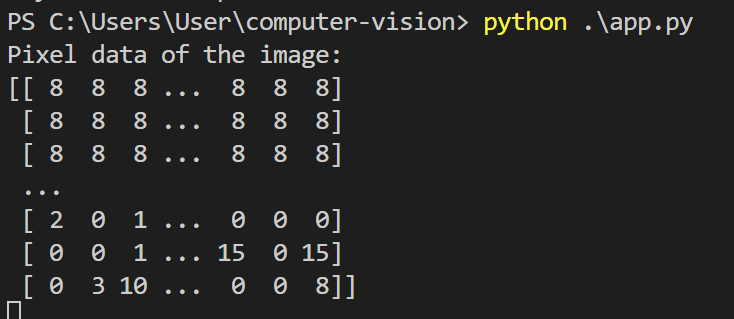
ภาพแต่ละจุดเล็กๆ (เรียกว่า “พิกเซล”)

จะถูกแปลงเป็นตัวเลขที่แสดงถึงสีและความสว่าง เช่น จุดหนึ่งอาจจะมีสีแดงมาก สีเขียวน้อย หรือเป็นสีขาวที่สว่างจ้า

จากภาพนี้เราจะเห็นได้ว่าเป็นภาพขนาด 10 ×10 =100 พิกเซล
แต่ละพิกเซลเป็นตัวเลขที่บ่งบอกระดับของสีและความสว่าง ตัวอย่างเช่น:
- ภาพสี (RGB): แต่ละพิกเซลมี 3 ค่า ได้แก่ สีแดง (Red), สีเขียว (Green), และสีน้ำเงิน (Blue)
- ภาพขาวดำ: แต่ละพิกเซลมีค่าเดียวแสดงความสว่าง (ตั้งแต่ 0 = ดำ ถึง 255 = ขาว)
ตัวอย่างถัดมาเราจะย่อให้ Pixel ขนาดน้อยลงขึ้น เพื่อให้เราเข้าใจง่าย เป็นขนาด 4×4 พิกเซล (รวมทั้งหมด 16 พิกเซล)

ภาพที่เราเห็นสามารถแสดงเป็นค่า RGB ที่ผสมกัน ความเข้มมากน้อยของสีแดง เขียว น้ำเงินจะทำให้เกิดสีต่าง ๆ โดยตัวอย่างนี้แอดจะแสดงให้เห็นว่าแต่ละ Pixel จะมีค่าสีแดง เขียว และน้ำเงินเป็นยังไง โดยจะระบุเป็นแบบแกน x, y และตามด้วยค่าของสี

- Pixel (0, 0): Red=0, Green=0, Blue=0
- พิกเซลที่มุมซ้ายบนสุด ไม่มีสี (ดำ)
- พิกเซลที่มุมซ้ายบนสุด ไม่มีสี (ดำ)
- Pixel (1, 0): Red=50, Green=0, Blue=30
- พิกเซลที่แถวบน (x=1) มีค่าสีแดง 50, ไม่มีสีเขียว, และสีน้ำเงิน 30
โดยค่าสีถ้าเราเพิ่มจากความสว่างได้ตั้งแต่ 0 -255 เช่น ผมสร้างอาร์เรย์สีแดง (Red) ที่มีค่า 0 ถึง 255

แล้วสีต่าง ๆ ที่ออกมามันจะเกิดจากการผสมสี Red, Green และ Blue เราก็จะมีสีที่หลากหลายไปประกอบเป็นภาพ
แล้วคอมได้ไงว่ารูปนี้คือรูปอะไร เช่น หมา แมว
คอมพิวเตอร์ไม่รู้จักหมาหรือแมวตั้งแต่แรกหรอกครับบ แต่เราต้องสอน สอนให้คอมเข้าใจว่ารูปนี้คืออะไร โดยการเอารูปหมานับร้อยนับพันไปเทรนให้แล้วบอกว่า “นี่คือหมา” และ “นี่คือแมว” จากนั้นคอมพิวเตอร์จะจำลักษณะเฉพาะของหมาและแมว เช่น หูแหลม ตากลม ขนสั้น หรือขนยาว
การทำให้คอมพิวเตอร์เข้าใจภาพต้องอาศัยกระบวนการที่เรียกว่า Machine Learning (การเรียนรู้ของเครื่อง) หรือ Deep Learning (การเรียนรู้เชิงลึก) โดยมีขั้นตอนหลักดังนี้
(1) การเก็บข้อมูล (Data Collection)
- เก็บภาพจำนวนมากที่เกี่ยวข้องกับสิ่งที่ต้องการให้คอมพิวเตอร์เข้าใจ เช่น ภาพสุนัข แมว หรือวัตถุอื่น ๆ
- ข้อมูลนี้เรียกว่า Dataset
(2) การเตรียมข้อมูล (Data Preprocessing)
- แปลงภาพให้มีขนาดหรือรูปแบบที่เหมาะสม เช่น ปรับขนาดภาพให้เท่ากัน
- แยกข้อมูลออกเป็น 2 ส่วน:
- Training Set: สำหรับใช้ในการสอน
- Testing Set: สำหรับใช้ในการทดสอบผลลัพธ์
(3) การสร้างโมเดล (Model Building)
- ใช้ Neural Networks (โครงข่ายประสาทเทียม) โดยเฉพาะ Convolutional Neural Networks (CNNs) ซึ่งออกแบบมาเฉพาะสำหรับการประมวลผลภาพ
- CNNs ทำงานโดยการ:
- Convolution: ดึงคุณสมบัติต่าง ๆ ของภาพ เช่น ขอบ, รูปทรง
- Pooling: ลดขนาดข้อมูล แต่ยังคงคุณสมบัติสำคัญ
- Fully Connected Layers: สร้างการเชื่อมโยงเพื่อสรุปผล
(4) การฝึกโมเดล (Training the Model)
- ให้โมเดลเรียนรู้จาก Training Set ด้วยการปรับค่าของโครงข่ายผ่าน Optimization Algorithm เช่น Gradient Descent
- ใช้ Loss Function ในการวัดความผิดพลาดระหว่างผลลัพธ์ที่ได้กับผลลัพธ์ที่ถูกต้อง
(5) การประเมินผล (Evaluation)
- ทดสอบโมเดลกับ Testing Set เพื่อตรวจสอบว่าโมเดลเข้าใจภาพได้ดีเพียงใด
- วัดผลด้วยค่าความแม่นยำ (Accuracy) หรือค่าความผิดพลาด (Error)
(6) การปรับปรุง (Improvement)
- หากผลลัพธ์ยังไม่ดีพอ อาจต้อง:
- เพิ่มข้อมูลใน Dataset
- ปรับเปลี่ยนโครงสร้างของโมเดล
- ใช้เทคนิคต่าง ๆ เช่น Data Augmentation (การปรับแต่งข้อมูล)
ตัวอย่างการใช้งาน
- จดจำใบหน้า (Face Recognition): เช่น ระบบปลดล็อกโทรศัพท์ด้วยใบหน้า
- วิเคราะห์ภาพทางการแพทย์ (Medical Imaging): เช่น ตรวจหามะเร็งจากภาพเอกซเรย์
- รถยนต์ไร้คนขับ (Self-Driving Cars): ใช้ในการตรวจจับถนนและสิ่งกีดขวาง
- ค้นหาภาพ (Image Search): เช่น การค้นหาภาพใน Google ด้วยภาพอื่น
สรุปแล้ว Computer Visioช่วยให้คอมพิวเตอร์เข้าใจโลกผ่านภาพและวิดีโอในแบบที่มนุษย์มองเห็น ความสามารถนี้ช่วยพัฒนาเทคโนโลยีในหลากหลายด้าน ตั้งแต่การจดจำใบหน้าในมือถือ การช่วยวินิจฉัยโรคในทางการแพทย์ ไปจนถึงการควบคุมรถยนต์ไร้คนขับ
สิ่งสำคัญคือ Computer Vision ไม่ได้เกิดขึ้นเอง แต่ต้องอาศัยการสอนและการเรียนรู้ด้วย Machine Learning และ Deep Learning นั่นเองครับ 😊




