

บริษัทลูลู่ เทคโนโลยี จำกัด (looloo technology) ร่วมกับ อ.ดร.ฐิติพัทธ อัชชะกุลวิสุทธิ์, อติรุจ บริบาลบุรีภัณฑ์ และ Mr. Zaw Htet Aung คณะวิศวกรรมชีวการแพทย์ มหาวิทยาลัยมหิดล พัฒนาโมเดลถอดความเสียงพูดภาษาไทย (Automatic Speech Recognition, ASR) ใช้ชื่อว่า ธนบุเรี่ยนวิสเปอร์ (Thonburian Whisper) ที่พัฒนาเพิ่มเติมจากโมเดล Whisper ของ OpenAI ระหว่างงาน Huggingface Whisper Fine-tuning
โมเดลถูกนำมาเรียนรู้เพิ่มเติมด้วยข้อมูลเปิดภาษาไทย ได้แก่ Commonvoice ที่เป็นชุดข้อมูลเปิดจากการบริจาคเสียงภาษาไทย, ข้อมูลเปิดของ Gowajee โดยบริษัท Gowajee, และข้อมูลเปิดของ Thai Elderly Dataset โดยบริษัท VISAI และ Data Wow ที่มีข้อความเสียงรวมความยาวกว่า 161 ชั่วโมงเพื่อให้ทำงานได้ดีกับภาษาไทย
โดย Thonburian Whisper มีขนาด 770 ล้านพารามิเตอร์ วัดผลด้วยข้อมูลชุดเทสของ Commonvoice 11 ได้ความผิดพลาดระดับคำ (Word error rate, WER) เท่ากับ 9.17 ทัดเทียมโมเดล ASR ในปัจจุบัน และเป็นโมเดลตัวเลือกเพิ่มเติมหลังจากสถาบันวิจัยปัญญาประดิษฐ์ประเทศไทย (AIResearch) และทีม PyThaiNLP ได้ปล่อยโมเดล ASR เปิดออกมาในปีที่แล้ว
ธนบุเรี่ยนวิสเปอร์: โมเดลถอดความจากเสียงพูดภาษาไทยที่พัฒนาต่อจากโมเดลของ OpenAI พัฒนาโดยบริษัทลูลู่ เทคโนโลยีและวิศวกรรมชีวการแพทย์ ม.มหิดล
 “ต่อยหม้อข้าวหม้อแกงให้จงสิ้น แล้วเทรนโมเดลวิสเปอร์ให้ใช้ได้ในตอนเช้า”
“ต่อยหม้อข้าวหม้อแกงให้จงสิ้น แล้วเทรนโมเดลวิสเปอร์ให้ใช้ได้ในตอนเช้า”
ชาวเอไอ ฝั่นธนฯ (ไม่ได้กล่าว)
โมเดลถอดความเสียงพูดภาษาไทย (Automatic Speech Recognition, ASR) เป็นโมเดลที่มีบทบาทอย่างมากในหลากหลายการใช้งาน ในปัจจุบัน ASR ถูกนำมาใช้ในแอพพลิเคชั่น เช่น Amazon Alexa, Apple Siri, และ Google Assistant ที่คนทั่วไปเข้าถึงได้ผ่านแอพพลิเคชั่นมือถือและคอมพิวเตอร์ นอกจากนั้น ASR ยังถูกนำมาใช้ในการถอดข้อความจากเสียงโทรศัพท์ วีดีโอ ภาพยนตร์ หรือระหว่างกีฬาและการแคสเกมได้อีกด้วย ดังนั้น ASR จึงเป็นโมเดลที่มีความสำคัญอย่างยิ่งสำหรับการต่อยอดแอพพลิเคชั่นในหลากหลายสาขา
ในปัจจุบันมี โมเดลเปิด ASR ภาษาไทยที่ผู้ใช้งานสามารถนำไปใช้ได้ เช่นโมเดล Wav2vec2 ที่ถูกสร้างขึ้นโดยบริษัท Facebook (Meta ในปัจจุบัน) และถูกนำมาพัฒนาให้ใช้งานกับภาษาไทยโดย AIResearch.in.th ซึ่งเป็นโมเดลเปิด ASR นอกจากนั้นยังมี API สำหรับระบบรู้จำข้อความเสียงภาษาไทย เช่นของบริษัท Gowajee และ iApp ASR ที่ทำให้ผู้ใช้งานสามารถนำไปประยุกต์ใช้กับงานต่างๆได้
เพื่อเพิ่มความหลากหลายของโมเดลเปิด ASR กลุ่มนักพัฒนาจากบริษัทลูลู่ เทคโนโลยี จำกัด (looloo technology) และ Biomedical and Data Lab คณะวิศวกรรมชีวการแพทย์ มหาวิทยาลัยมหิดล จึงร่วมกันพัฒนาโมเดลถอดความเสียงพูดภาษาไทย (Automatic Speech Recognition, ASR) ทางเลือก ใช้ชื่อว่า Thonburian Whisper ที่พัฒนาเพิ่มเติมจากโมเดล Whisper ที่ถูกสร้างจาก OpenAI ถูกที่ปล่อยออกมาในช่วงเดือนกันยายนปี ค.ศ. 2022 ที่ผ่านมา โดยการพัฒนาโมเดลนี้เป็นส่วนหนึ่งของ Huggingface Whisper Fine-Tuning Event ที่จัดขึ้นในเดือนธันวาคมที่ผ่านมา
Whisper คืออะไร?
Whisper เป็นโมเดล ASR ที่ถูกพัฒนาโดยบริษัท OpenAI ซึ่งถูกเทรนด้วยไฟล์เสียงหลายภาษาจำนวนมากกว่า 680,000 ชั่วโมง จึงทำให้โมเดลมีความสามารถในการทำความเข้าใจลักษณะของสัญญาณเสียงในเชิงเวลาและความถี่ได้ดีมาก โดยความสามารถในการถอดข้อความภาษาอังกฤษของ Whisper ในภาษาอังกฤษมีความแม่นยำเข้าใกล้การถอดความของคน (human-level) แต่ทั้งนี้โมเดล Whisper ได้ถูกสร้างขึ้นเพื่อใช้กับภาษาอังกฤษและแบบหลายภาษาเป็นหลัก การนำมาใช้งานในภาษาไทยนั้นจึงจำเป็นต้องมีการเทรนเพิ่มเติม (Fine-tune) กับชุดข้อมูลสัญญาณเสียงภาษาไทยก่อนเพื่อให้โมเดลเรียนรู้ และใช้กับภาษาไทยได้อย่างแม่นยำยิ่งขึ้น
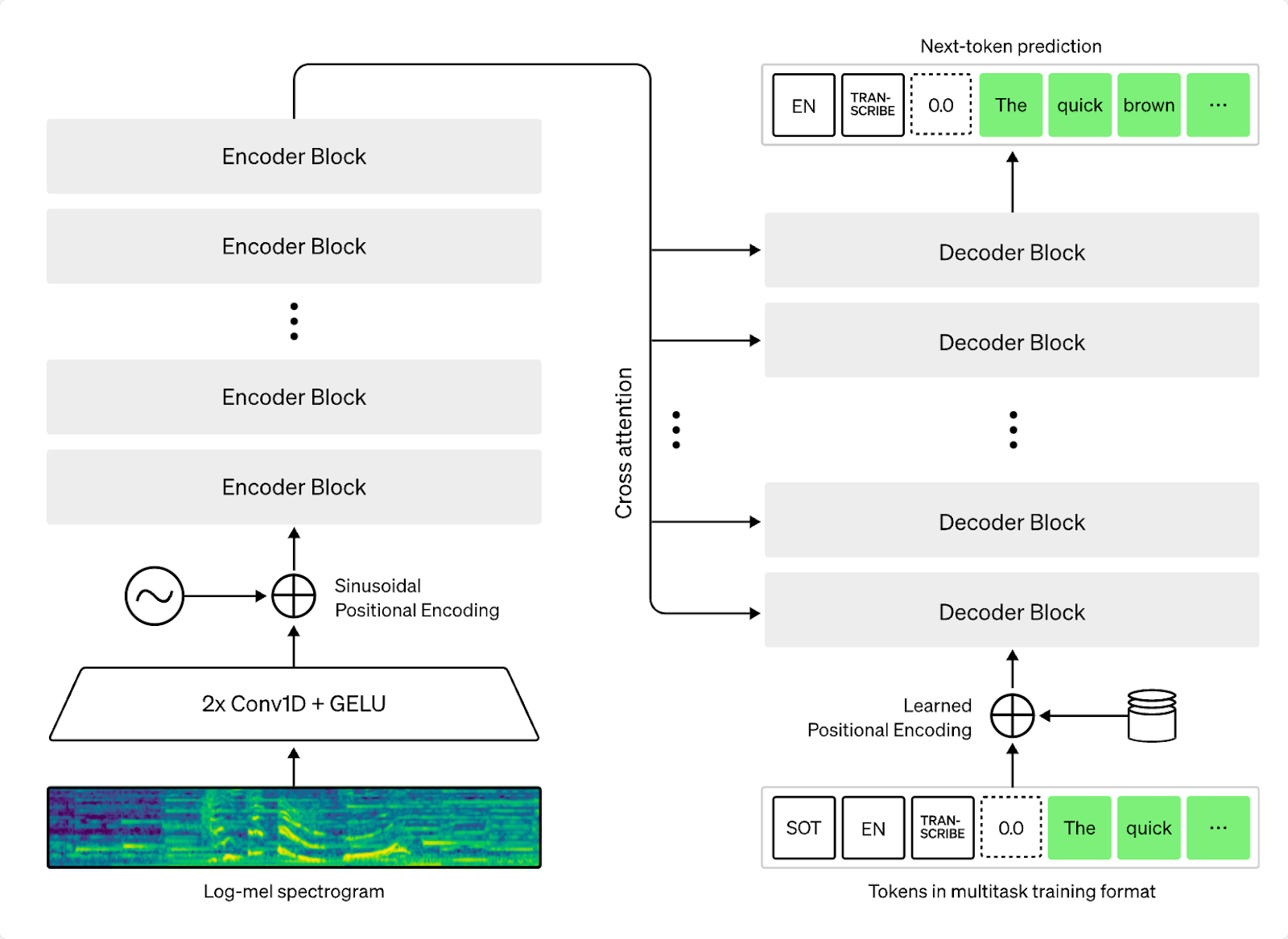 สถาปัตยกรรมการทำงานของโมเดล Whisper ประกอบด้วย Encoder และ Decoder blocks
สถาปัตยกรรมการทำงานของโมเดล Whisper ประกอบด้วย Encoder และ Decoder blocks
ที่รับ log-Mel Spectogram
ที่มา: Radford, Alec, et al. “Robust speech recognition via large-scale weak supervision.”
OpenAI Blog (2022). Github: https://github.com/openai/whisper
Whisper ทำงานอย่างไร?
Whisper ถูกสร้างขึ้นด้วยสถาปัตยกรรมแบบ end-to-end ที่มี Transformer เป็น Encoder และ Decoder ของโมเดล โดย Whisper เทรนโดยใช้ข้อมูลเสียงความยาวกว่า 680,000 ชั่วโมง วิธีการคือเปลี่ยนจากไฟล์สัญญาณเสียงให้เป็น log-Mel spectrogram ให้ Encoder และ Decoder เพื่อทำนายภาษาแบบหลายภาษาและภาษาอังกฤษภาษาเดียว เนื่องจาก Whisper ใช้ข้อมูลเสียงจากหลายภาษาในการสร้างโมเดล ทำให้มีความสามารถในการบีบอัดข้อมูลเสียงอย่างมีประสิทธิภาพ
สำหรับการประมวลผลข้อความก่อนเทรนโมเดลนั้น เราใช้วิธีการประมวลผลแบบน้อยที่สุด (Minimalist approach) คล้ายกับต้นฉบับเปเปอร์ของโมเดล Whisper โดยทำความสะอาดภาษาไทยมาตรฐาน เช่นเปลี่ยนสระเอ 2 ตัว (เเ) เป็นสระแอ (แ), การเขียนสระอำผิด, รวมถึงลบเครื่องหมายวรรคตอน เช่น “, -, –, !
แต่เราไม่ได้ทำการตัดคำ (word tokenize) ไม่เปลี่ยนไม้ยมก (ๆ) ให้เป็นคำที่มาก่อนหน้า เช่น “เดี๋ยวเจอกันบ่อยๆ” เป็น “เดี๋ยวเจอกันบ่อย บ่อย” และไม่ได้เปลี่ยนตัวเลขให้เป็นคำอ่าน แน่นอนว่าการนำโมเดลมาทำนายอาจเกิดความผิดพลาดมากกว่าแต่ว่าเป็นการเลือกของผู้พัฒนา (development choice) โดยข้อดีของการเลือกใช้การประมวลผลที่น้อยทำให้ช่วยลดการ post process หลังจากโมเดลทำนายผลอีกด้วย
ความแตกต่างของ Whisper และ Wav2Vec2
ความแตกต่างโดยสังเขปของโมเดล Whisper ของ OpenAI และ Wav2Vec2 ของ Facebook AI Research (FAIR) ที่ทาง AIResearch.in.th ได้ปล่อยออกมาในปี ค.ศ. 2021 คือโมเดลทั้งสองใช้สถาปัตยกรรมของ Encoder ที่แตกต่างกัน โดย Whisper ใช้ Transformer เพื่อรับ Log-mel spectrogram แต่ว่า Wav2vec2 ใช้สถาปัตยกรรมที่สามารถดึง latent representation จากสัญญาณเสียง นอกจากนั้นแล้วในฝั่ง Decoder ของ Wav2vec2 จะใช้การทำนายตัวอักษร ส่วน Whisper จะใช้การทำนายด้วย GPT2 tokens (โดยการใช้โมเดล GPT2 ในการ tokenize ประโยคหรือคำที่เข้ามา)
จำนวนพารามิเตอร์ของ Whisper ขนาด tiny, base, small, medium, large เท่ากับ 39M, 74M, 244M, 769M, 1550M ตามลำดับ ส่วน Wav2vec2 มีขนาดเท่ากับ 317M
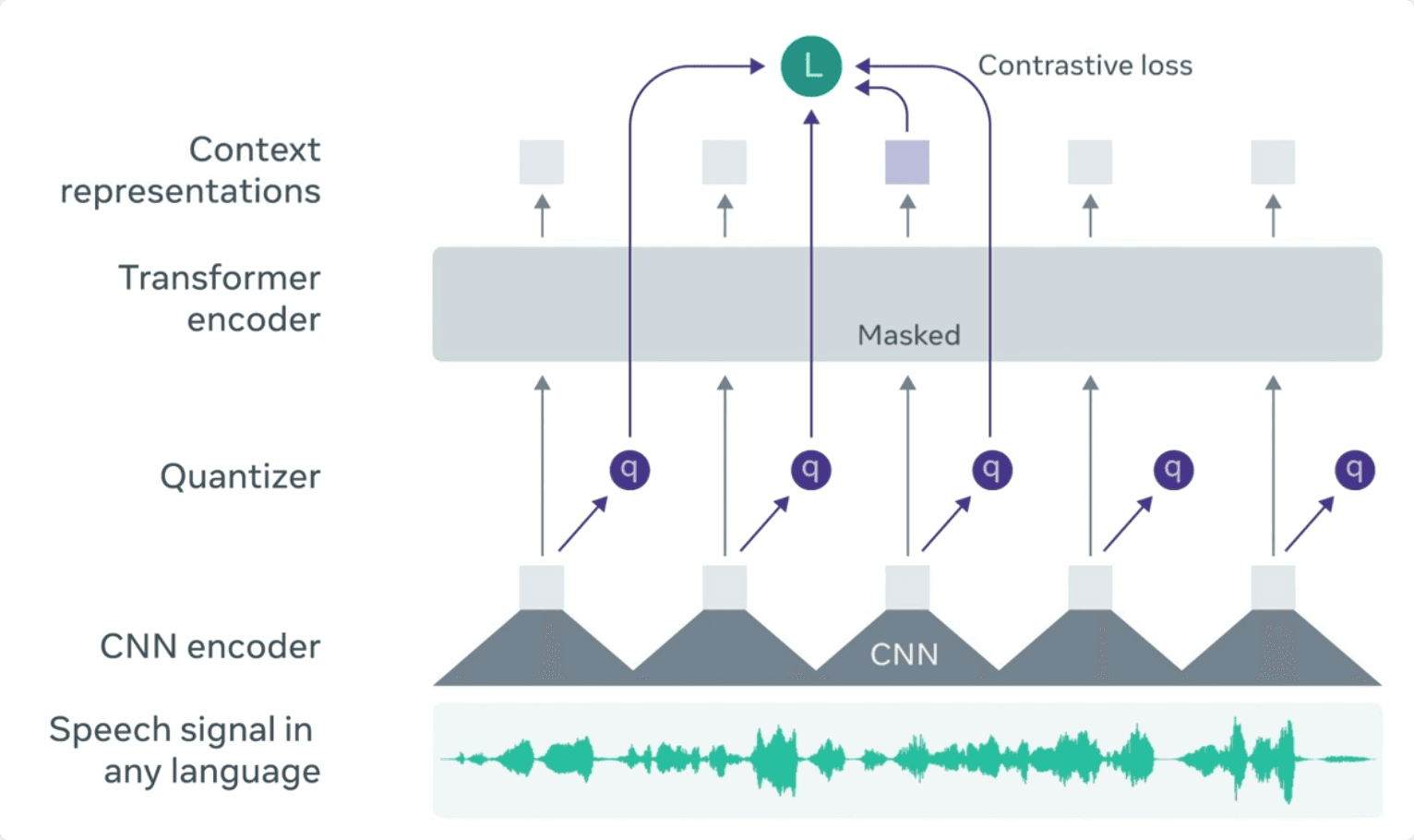
สถาปัตยกรรมของ Wav2vec2 ประกอบด้วย CNN encoder, Quantizer, Transformer,
และ Context representation โดยมีสัญญาณเสียงใน time-domain เป็น input
ที่มา: https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/
ทำไมต้อง Fine-tune โมเดล Whisper เพื่อใช้กับภาษาไทย?
ถึงแม้ว่าโมเดล Whisper จะถูกสร้างขึ้นเพื่อตรวจจับหลายภาษา แต่ว่าการทำงานในภาษาไทยอย่างเดียวนั้นยังมีความผิดพลาดของการทำนายที่สูง การ Fine-tune โมเดล Whisper จึงสามารถทำให้โมเดลมีความผิดพลาดของการทำนายที่น้อยลงได้ ทั้งนี้บริษัท Huggingface ได้เล็งเห็นความสำคัญและจัดงาน Whisper
fine-tuning sprint เพื่อให้ผู้พัฒนานำโมเดล Whisper มา fine-tune ให้เหมาะสมกับภาษาต่างๆ ทั้งนี้ทีมได้เข้าร่วมการ sprint ในครั้งนี้เพื่อพัฒนาโมเดล Whisper ที่มีความเหมาะสมกับภาษาไทย และเปิดโมเดลเป็นสาธารณะให้กับนักพัฒนาและผู้ใช้งานทั่วไปได้ทดลองใช้กัน เพิ่มความหลากหลายของตัวเลือกโมเดล ASR ที่มีในปัจจุบัน
Fine-tune Thonburian Whisper (ธนบุเรี่ยนวิสเปอร์)
ธนบุเรี่ยนวิสเปอร์ถูกเทรนจากโมเดล Whisper เป็นโมเดลตั้งต้น ดังที่กล่าวข้างต้น Whisper มีหลายขนาดให้เลือกตั้งแต่ tiny, base, small, medium, large เราเลือกเทรนโมเดล 2 ขนาดคือ small และ medium โดยขนาดที่พบว่าทำงานได้ดีที่สุดคือขนาด medium โดยโมเดลขนาด medium มีจำนวนพารามิเตอร์ประมาณ 770 ล้านพารามิเตอร์ เราเทรนโมเดล Whisper สำหรับภาษาไทยด้วยชุดข้อมูลเปิด Commonvoice ที่ได้รับบริจาคเสียงภาษาไทยจากมากกว่า 7000 คน, ข้อมูลเปิดของ Gowajee โดยบริษัท Gowajee, และข้อมูลเปิดของ Thai Elderly Dataset
โดยบริษัท VISAI และ Data Wow หลังจากเทรนโมเดลเรียบร้อย เรานำโมเดลมาวัดผลด้วยความผิดพลาดระดับคำ Word Error Rate (WER) ในข้อมูลชุดเทสของ Commonvoice 11 โดยตัดคำด้วยตัวตัดคำ Deepcut เท่ากับ 9.17* โมเดลมีความผิดพลาดใกล้เคียงกับโมเดล ASR ในปัจจุบัน และเป็นโมเดลตัวเลือกเพิ่มเติมหลังจากสถาบันวิจัยปัญญาประดิษฐ์ประเทศไทย (AIResearch.in.th) และทีม PyThaiNLP ได้ปล่อยโมเดล ASR เปิดมาในปีที่แล้ว
*แบ่งข้อมูล train, test ของ Commonvoice ตามไลบรารี่ huggingface/datasets
*ทำความสะอาดข้อความโดยลบเครื่องหมายวรรคตอนก่อนวัดผล
ผลการทำนายและประสิทธิภาพของโมเดล
โดยรวมนั้นโมเดลสามารถทำนายคำได้ค่อนข้างแม่นยำแต่ยังมีความผิดพลาดอยู่บ้าง โดยเราได้ยกตัวอย่างตารางผลการทำนายสำหรับข้อมูลชุดเทส Commonvoice 11 ที่โมเดลทำนายผิดพลาดดังนี้
| ข้อความจริง (transcript) | ผลการทำนาย (prediction) |
| แซ็กอยากเป็นนักเก็ต | แซคอยากเป็นนักเก๊ต |
| แยกอะตอมไฮโดรเจนออกจากโมเลกุลไซยาไนด์ | แยกอตอมไฮโดรเจนออกจากโมเลกุลไซยานัย |
| เซลขายของที่เก่งมักจะโน้มน้าวให้ลูกค้าใช้อารมณ์ในการตัดสินใจซื้อสินค้ามากกว่าใช้เหตุผล | เซลล์ขายของที่เก่งมักจะโน้มน้าวให้ลูกค้าใช้อารมณ์ในการตัดสินใจซื้อสินค้ามากกว่าใช้เหตุผล |
| มันเป็นผลลัพธ์ทางอ้อม | มันเป็นผลลัพทางอ้อม |
| ฉันไม่รู้มาก่อนเลยว่าคุณเล่นกีต้าร์ด้วย | ฉันไม่รู้มาก่อนเลยว่าคุณเล่นกีธาด้วย |
| ตอบรับ | ตอบลับ |
| น้ำมันเบรกไหลออกจากทาง | น้ำมันเบกไหลออกจากทาง |
| นายตำรวจพูดว่าคดีฆาตกรรมทำให้เขาปวดหัว | นายตำรวจพูดว่าคดีฆาตุกรรมทำให้เขาปวดหู |
จะเห็นว่าโมเดลยังมีความผิดพลาดในการสะกดคำอยู่ เช่น แซ็กเขียนเป็นเป็นแซค ไซยาไนด์เป็นไซยานัย สับสนระหว่าง ร กับ ล และวรรณยุกต์ที่ผิดอยู่บ้าง เช่น นักเก็ตเป็นนักเก๊ต ปัจจัยหนึ่งอาจเกิดจากความผิดพลาดเนื่องจาก Whisper ไม่ได้ใช้โมเดลภาษา (language model) ในการทำนายผล


ผู้พัฒนาลองนำวีดีโอของน้องใจดีมาทดลองถอดความได้ผลตามข้างต้น โดยรวม Thonburian Whisper
สามารถทำนายได้ดีแต่ยังมีการผิดอยู่บ้าง เช่น กระเผกเป็นกระเพก เห้ยล้อเล่นเป็นโหยล้อนเล่น มีค่าเป็นนิค่ะ
(ที่มาวิดีโอ: https://www.youtube.com/shorts/v0S0hJfZZY8)
สำหรับความเร็วในการ inference นั้น เบื้องต้นเราได้ทดลอง inference ไฟล์เสียงตัวอย่างในความยาวต่างๆจำนวน 1000 ไฟล์ (ความยาวเฉลี่ย 5.02 วินาทีต่อไฟล์) ด้วยการ์ดจอ RTX3060 พบว่า Thonburian Whisper (medium) ใช้ระยะเวลาเฉลี่ย 1.8 วินาที/ไฟล์ ส่วน Wav2vec-XLSR ใช้ระยะเวลาเฉลี่ย 0.054 วินาที/ไฟล์ ผู้พัฒนายังเห็นว่าความเร็วในการ inference ของ Whisper ยังช้ากว่า Wav2vec-XLSR หลายเท่าตัวอยู่ แต่ก็ยังมีข้อดีอื่นๆของโมเดล Whisper เช่นสามารถนำมาใช้แปลภาษาและถอดความภาษาไทยร่วมกับเวลาเริ่ม-หยุด (timestamps) ได้
โมเดลเปิดให้ใช้ฟรีด้วยไลบรารี่ Huggingface transformers
สำหรับผู้ที่สนใจใช้งาน Thonburian Whisper สามารถทดลองใช้งานผ่านช่องทางดังนี้
-
ดาวน์โหลดโมเดลจาก https://huggingface.co/biodatlab/whisper-th-medium-combined และใช้งานผ่านไลบรารี่ huggingface transformers (วิธีใช้ตามรูปด้านล่าง)
-
ทดลองใช้งานผ่าน Google Colab ที่ https://colab.research.google.com/github/biodatlab/whisper-th-demo/blob/main/whisper_th_demo.ipynb
-
อ่านโค้ดทาง Github https://github.com/biodatlab/whisper-th-demo
หรือทดลองใช้โมเดลทำนายข้อความเสียงแบบสั้นผ่าน Demo: huggingface spaces ที่ https://huggingface.co/spaces/biodatlab/whisper-thai-demo (ทีมของเราได้ Community credit จาก Huggingface ให้ผู้ที่สนใจทดลองใช้ได้ฟรีถึง 21 ธันวาคม ค.ศ. 2022 นี้)
ใครที่ลองเล่น Thonburian Whisper แล้วก็มาคอมเม้นกันได้ในบล็อกนี้หรือส่งข้อเสนอแนะผ่านโพสต์ของเราเพจเฟซบุ๊คได้ที่ https://www.facebook.com/loolootech
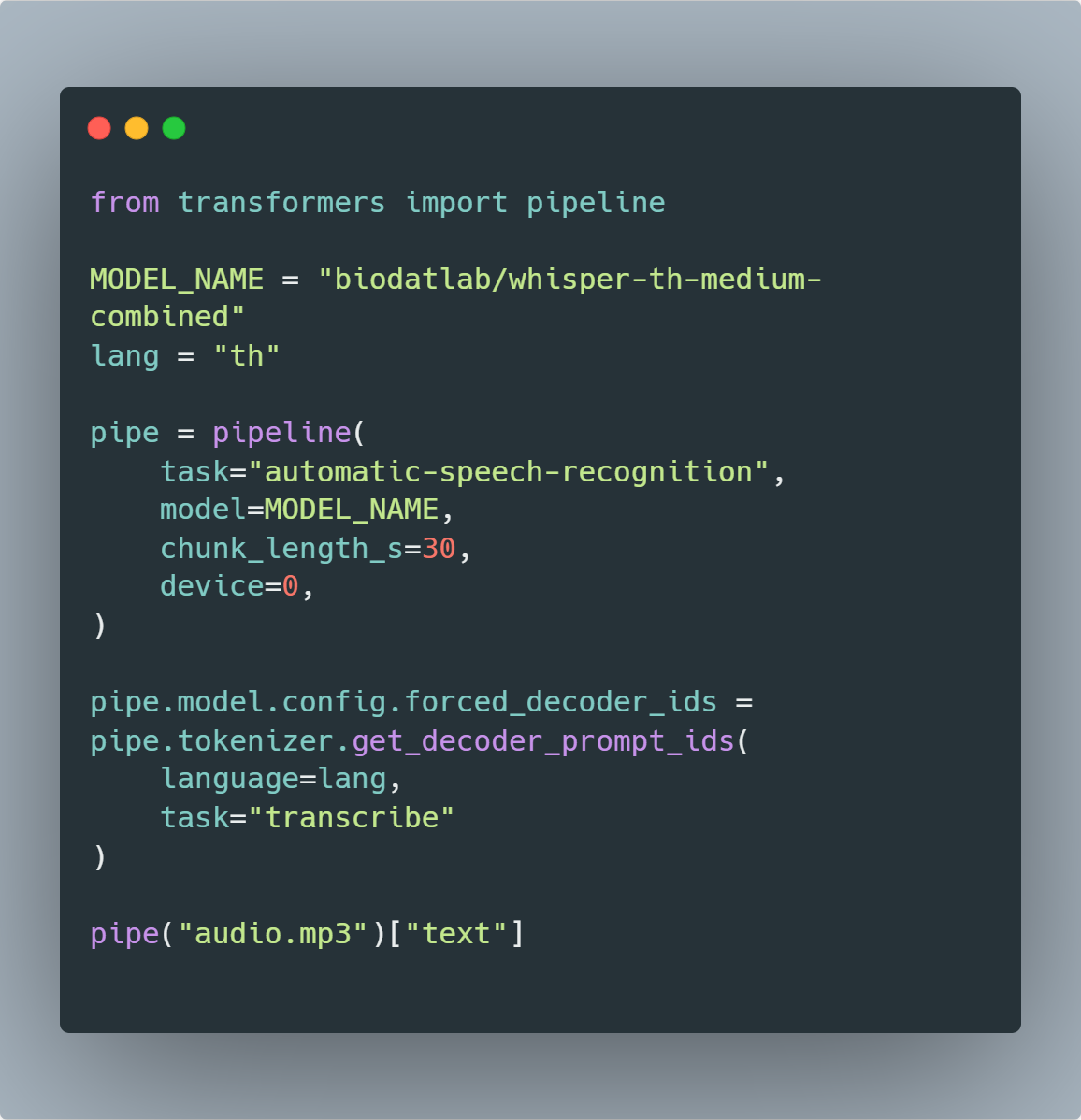 ตัวอย่างวิธีใช้งานธนบุเรี่ยนวิสเปอร์ (Thonburian Whisper) ด้วยไลบรารี่ huggingface transformers โดยการสร้าง pipeline, เลือกโมเดล, ทำนายผล
ตัวอย่างวิธีใช้งานธนบุเรี่ยนวิสเปอร์ (Thonburian Whisper) ด้วยไลบรารี่ huggingface transformers โดยการสร้าง pipeline, เลือกโมเดล, ทำนายผล
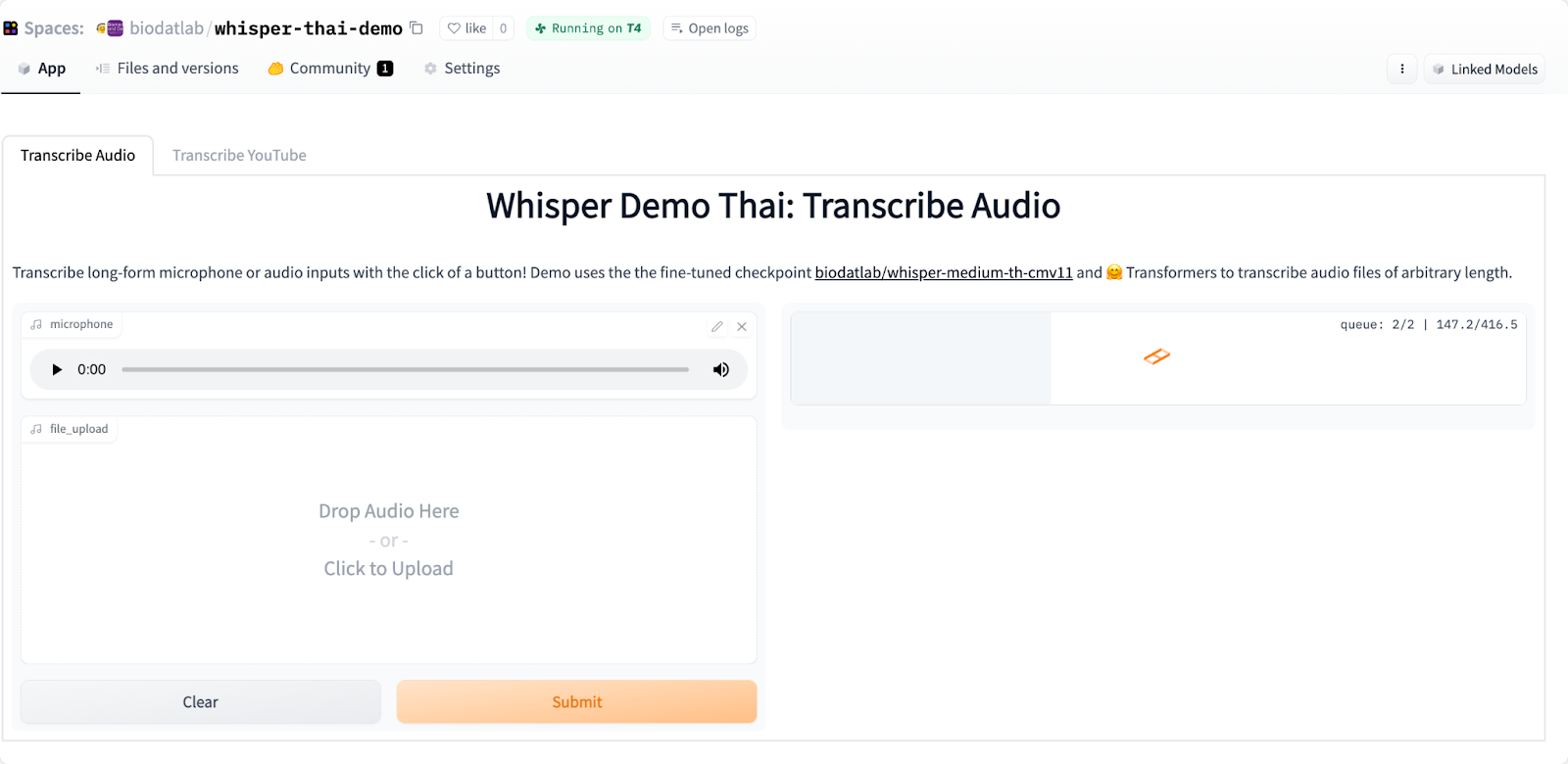 ตัวอย่างใช้งานโมเดลธนบุเรี่ยนวิสเปอร์ (Thonburian Whisper) ผ่านแอพพลิเคชั่น Gradio ผ่าน huggingface spaces https://huggingface.co/spaces/biodatlab/whisper-thai-demo
ตัวอย่างใช้งานโมเดลธนบุเรี่ยนวิสเปอร์ (Thonburian Whisper) ผ่านแอพพลิเคชั่น Gradio ผ่าน huggingface spaces https://huggingface.co/spaces/biodatlab/whisper-thai-demo
เกี่ยวกับเรา กลุ่มชาวเอไอฝั่งธนฯเป็นกลุ่มของนักพัฒนาจากหลายบริษัทฝั่งธนฯ ที่อยู่อาศัยและใช้ชีวิตกันแถบฝั่งตะวันตกของแม่น้ำเจ้าพระยาหรือว่าฝั่งธนบุรี กลุ่มนี้ชอบโพสต์อาหารยามดึกนัดกินข้าวกันในยามวิกาล พวกเค้านั้นไม่ค่อยมีหลักแหล่ง สามารถติดต่อได้ตามกลุ่มเฟสบุ๊ค เราเลือกใช้ชื่อโมเดล Thonburian Whisper เพื่อให้เครดิตกับถิ่นฐานที่เติบโตมา
Acknowledgement ทางทีมผู้พัฒนาขอบคุณคุณ Charin Polpanumas ที่ให้ข้อเสนอแนะสำหรับบทความ
พัฒนาด้วย ❤️ โดยตัวแทนชาวเอไอฝั่งธนฯ Atirut Boribalburephan, Zaw Htet Aung, Titipat Achakulvisut, และ Knot Pipatsrisawat (จาก Biomedical and Data Lab, MU และบริษัทลูลู่ เทคโนโลยี) www.loolootech.com

หากคุณสนใจพัฒนา สตาร์ทอัพ แอปพลิเคชัน
และ เทคโนโลยีของตัวเอง ?
อย่ารอช้า ! เรียนรู้ทักษะด้านดิจิทัลเพื่ออัพเกรดความสามารถของคุณ
เริ่มตั้งแต่พื้นฐาน พร้อมปฏิบัติจริงในรูปแบบหลักสูตรออนไลน์วันนี้
-
Sale!

-
Sale!
-
Sale!
-
Sale!








