

 โดย Chaiyaphop Jamjumrat (Bas)
โดย Chaiyaphop Jamjumrat (Bas)
Data Scientist at True Digital Group
“Stop doing Data Sciyasart! Please, Do Data Science!”
What is a Decision Tree?
Decision Tree หรือ ต้นไม้ตัดสินใจ คือ การจำลองวิธีการตัดสินใจของมนุษย์ ซึ่งการตัดสินใจแต่ละครั้งของมนุษย์ มนุษย์จะแตกโจทย์หลักออกเป็นโจทย์ย่อยหลาย ๆ โจทย์ก่อนเพื่อที่จะได้ง่ายต่อการตัดสินใจ หรือจะนำเอาปัจจัยต่าง ๆ ที่เกี่ยวข้องกับการตัดสินใจหรือเกี่ยวข้องกับโจทย์หลักมาตั้งเป็นคำถามใหม่หรือแตกเป็นโจทย์ย่อย และถามตัวเองใหม่อีกครั้ง
เช่น วันนี้, มีเพื่อนมาถามเราว่าไปกินข้าวมันไก่ด้วยกันไหม? มนุษย์อย่างเราจะคิดก่อนว่า เอ๊ะ! อร่อยหรือเปล่านะ? ถ้าไม่อร่อยแล้วราคาแพงไหม? แล้วค่อยตัดสินใจว่าจะไปหรือไม่ไป
ทำไมถึงเรียกว่า Decision Tree หรือ ต้นไม้ตัดสินใจ?
เพราะว่าการแตกกิ่งความคิดหรือการแตกโจทย์ออกเป็นโจทย์ย่อย ๆ ของมนุษย์ก่อนที่จะตัดสินใจเนี้ย มันมีลักษณะเหมือนกับการแตกกิ่งของต้นไม้นั่นเอง
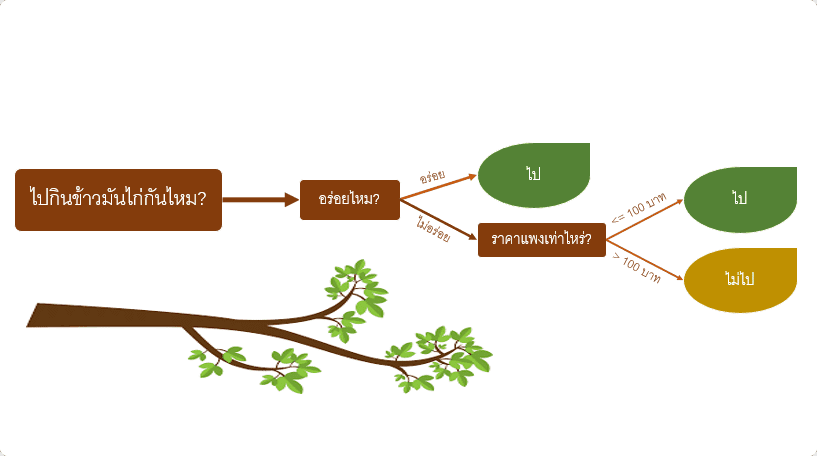
Model Decision Tree คืออะไร? และทำงานอย่างไร?
Model Decision Tree เป็น Rule-Based Model ที่จะสร้างเงื่อนไข If-else ขึ้นมาจากข้อมูลในตัวแปร เพื่อที่จะแบ่งข้อมูลออกเป็นกลุ่มใหม่ที่สามารถอธิบาย Target ได้ดีที่สุด โดยการสร้างเงื่อนไข If-else ในแต่ละตัวแปร จะถูกกำหนดด้วย Objective Function ซึ่ง Model Decision Tree มี Objective Function อยู่หลายตัว ตามประเภทของ Decision Tree นั้น ๆ
Decision Tree จะแบ่งออกเป็น 2 ประเภท คือ
-
-
Regression Tree คือ Decision Tree ที่ใช้สำหรับการทำโจทย์ Regression โดยมีค่า Residual sum of squares (RSS) เป็น Objective Function ในการหาจุดที่ดีที่สุดในการแบ่งข้อมูล (Split point) จากการ Minimize ให้ RSS มีค่าน้อยที่สุด
– Residual (e_i) คือ ค่าความคลาดเคลื่อน หรือค่า Error ระหว่าง y ทุก ๆ จุดในข้อมูล กับ y_hat ที่ได้มาจากการประมาณค่าขึ้นมาการคำนวณ Residual ของข้อมูลตัวที่ i
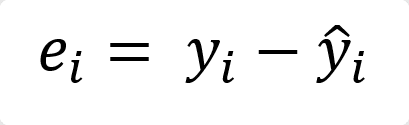
– Residual sum of squares (RSS) คือ การวัดค่า Residual หรือ ค่า Error ของทุก ๆ จุดในชุดข้อมูล และนำมายกกำลังสอง เพื่อให้ค่า Residual เป็นบวก และเป็นการทำ Normalize ด้วย เนื่องจากถ้า y_hat มีค่ามากกว่า yi จะทำให้ค่า Residual ติดลบ
การคำนวณ Residual sum of squares
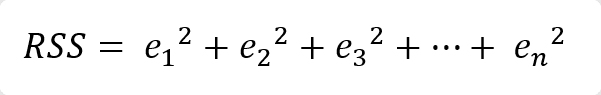
-
Classification Tree คือ Decision Tree ที่ใช้สำหรับการทำ Classification โดยจะใช้ Gini Impurity หรือ Entropy เป็น Objective Function ในการหาจุดที่ดีที่สุดในการแบ่งข้อมูล (Split point)
– Gini Impurity คือ การวัดค่า Impurity หรือ ค่าความไม่บริสุทธิ์ในการอธิบาย Target ของกลุ่มที่ถูกแบ่งออกมาจากตัวแปร นั่นหมายความว่าถ้าค่า Impurity ยิ่งต่ำก็ยิ่งแบ่งข้อมูลออกมาได้ดีนั่นเอง
– การคำนวณ Gini Impurity คือ การนำเอาผลรวมของค่าความน่าจะเป็นของเหตุการณ์ที่เราสนใจมาคูณด้วย (1 ลบ ค่าความน่าจะเป็นของเหตุการณ์ที่เราสนใจ)
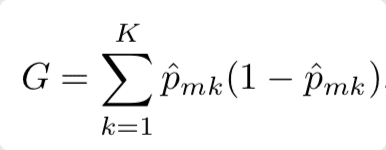 หลังจากได้ค่า Gini Impurity ของแต่ละกลุ่มในทุก ๆ ตัวแปรแล้ว จะทำการหาค่า Weighted Gini Impurity เพื่อเลือกตัวแปรที่มีค่า Weighted Gini Impurity ต่ำที่สุดมาใช้ในการตัดสินใจก่อน เพราะสามารถ Split ข้อมูลได้ดีที่สุด
หลังจากได้ค่า Gini Impurity ของแต่ละกลุ่มในทุก ๆ ตัวแปรแล้ว จะทำการหาค่า Weighted Gini Impurity เพื่อเลือกตัวแปรที่มีค่า Weighted Gini Impurity ต่ำที่สุดมาใช้ในการตัดสินใจก่อน เพราะสามารถ Split ข้อมูลได้ดีที่สุด
การคำนวณ Weighted Gini Impurity คือ การนำเอาผลรวมของค่า Gini ในเหตุการณ์ที่เราสนใจ คูณกับจำนวนข้อมูลของ Class ที่ i ในตัวแปรที่เราสนใจ และหารด้วยจำนวนข้อมูลทั้งหมดในตัวแปรที่เราสนใจ
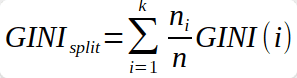
Example (Gini Impurity)
เรามาลองทำตัวอย่างง่าย ๆ ในการหาค่า Gini Impurity และ ค่า Weighted Gini Impurity กันครับ
.
ถ้าวันนี้เราจะชวนเพื่อนร่วมงานไปกินข้าวมันไก่ โดยให้เพื่อนร่วมงานทุกคนช่วยกันตัดสินใจว่าจะไปกินด้วยกันไหม และนำมาเก็บข้อมูลเพื่อหาค่า Gini Impurity และ Weighted Gini Impurity (สมมติให้เรามีเพื่อนร่วมงานทั้งหมด 10 คน และมีปัจจัยที่เกี่ยวข้องกับการไปกินข้าวมันไก่เพียงปัยจัยเดียว คือ ความอร่อย)
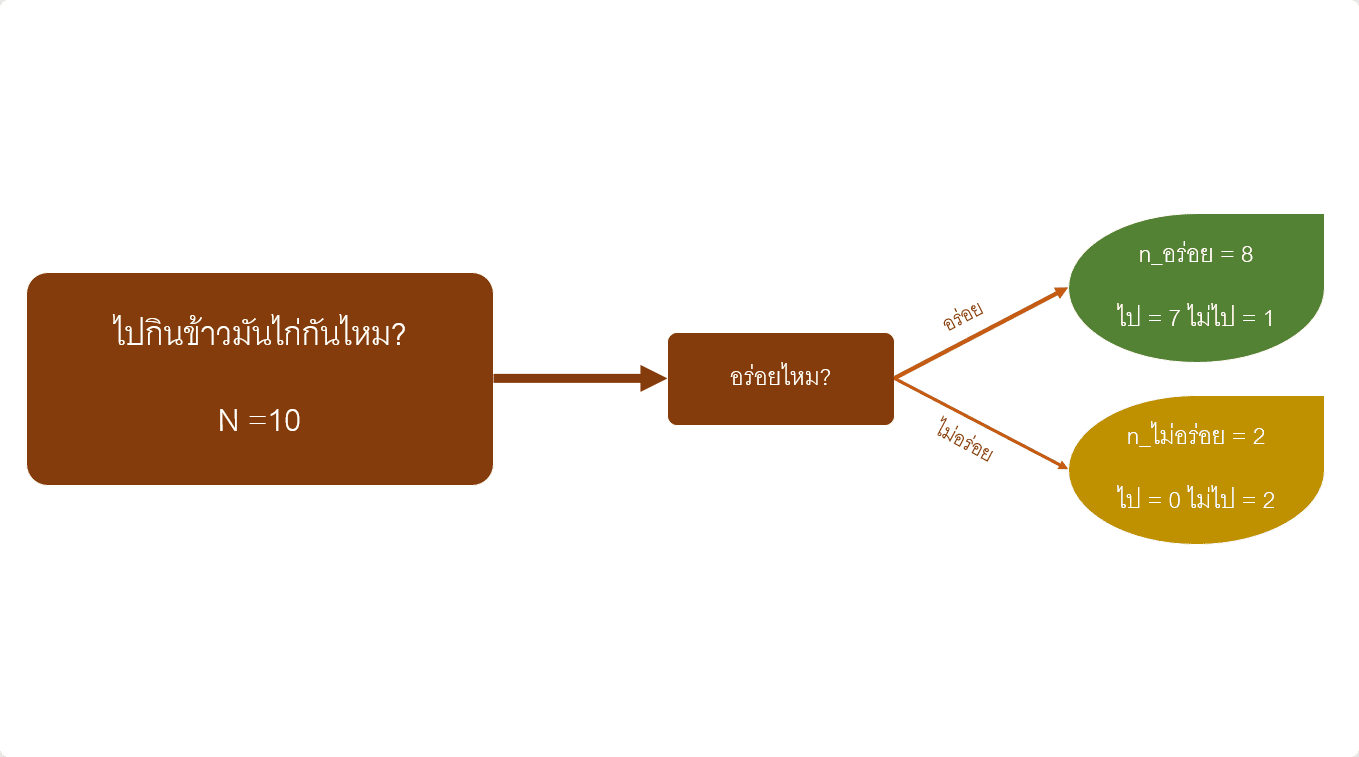
จากข้อมูลที่เก็บมา
– มีคนบอกว่าข้าวมันไก่ร้านนี้อร่อยทั้งหมด 8 คน แต่มีคนตกลง “ไป” แค่ 7 คน อีก 1 คน “ไม่ไป”
– มีคนบอกว่าข้าวมันไก่ร้านนี้ไม่อร่อย 2 คน และทั้ง 2 คน ตัดสินใจว่า “ไม่ไป”
การคำนวณ Gini Impurity
Gini Impurity(อร่อย) = [P(ไป|อร่อย) * (1-P(ไป|อร่อย)] + [P(ไม่ไป|อร่อย) * (1-P(ไม่ไป|อร่อย)]
P(ไป|อร่อย) = 7/8 = 0.875
P(ไม่ไป|อร่อย) = 1/8 = 0.25
G(อร่อย) = [0.875 * (1-0.875)] + [0.125 * (1-0.125)] = 0.21875
มีคนบอกว่าข้าวมันไก่ร้านนี้ไม่อร่อย 2 คน และทั้ง 2 คน ตอบว่าไม่ไป
Gini Impurity(ไม่อร่อย) = [P(ไป|ไม่อร่อย) * (1-P(ไป|ไม่อร่อย)] + [P(ไม่ไป|ไม่อร่อย) * (1-P(ไม่ไป|ไม่อร่อย)]
P(ไป|ไม่อร่อย) = 0/2 = 0
P(ไม่ไป|ไม่อร่อย) = 2/2 = 1
G(ไม่อร่อย) = [0 * (1-0)] + [1 * (1-1)] = 0
และนำค่า Gini Impurity ทั้ง 2 ตัวในปัจจัยความอร่อย มาหาค่า Weighted Gini Impurity
Weighted Gini Impurity(ความอร่อย) = [(n_อร่อย/N) * G(อร่อย)] + [(n_ไม่อร่อย/N) * G(ไม่อร่อย)] = [(8/10) * 0.21875] + [(2/10) * 0] = 0.175
-
-
-
Entropy คือ คือ การวัด Randomness (ความไม่แน่นอน) ในการอธิบาย Target ของกลุ่มที่ถูกแบ่งออกมาจาก Feature นั่นหมายความว่าถ้าค่า Randomness ยิ่งต่ำก็ยิ่งแบ่งข้อมูลออกมาได้ดี
-
การคำนวณ Entropy
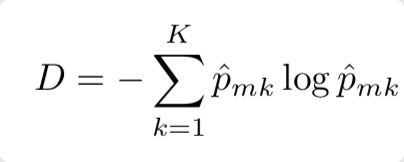
ซึ่งสมการก็จะคล้ายคลึงกับค่า Gini Impurity เลย แต่ Entropy จะเป็นการคูณด้วย Log ของค่าความน่าจะเป็นของเหตุการณ์ที่เราสนใจ แทนการคูณด้วย 1 ลบ ค่าความน่าจะเป็นของเหตุการณ์ที่เราสนใจของ Gini Impurity ทำให้ค่า Entropy จะอยู่ในช่วงระหว่าง 0 – 1 แต่ Gini Impurity อยู่ในช่วงระหว่าง 0 – 0.5
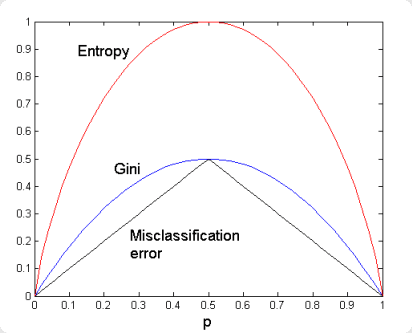
Relation among Entropy, Gini Index and Misclassification error.
อ้างอิงจาก
- building-and-visualizing-decision-tree-in-python สืบค้นเมื่อ 14 ก.ย. 2565 จาก: https://medium.com/codex/building-and-visualizing-decision-tree-in-python-2cfaafd8e1bb
- DECISION TREES, สืบค้นเมื่อ 14 ก.ย. 2565 จาก: https://dafriedman97.github.io/mlbook/content/c5/concept.html
หากคุณสนใจพัฒนา สตาร์ทอัพ แอปพลิเคชัน
และ เทคโนโลยีของตัวเอง ?
อย่ารอช้า ! เรียนรู้ทักษะด้านดิจิทัลเพื่ออัพเกรดความสามารถของคุณ
เริ่มตั้งแต่พื้นฐาน พร้อมปฏิบัติจริงในรูปแบบหลักสูตรออนไลน์วันนี้
-
ลดราคา!

-
ลดราคา!
-
ลดราคา!
-
ลดราคา!







