

สวัสดีครับในวันนี้ผมจะมาสอนทุกท่านทำ Sentiment Analysis ด้วย Bert แบบ คร่าว ๆ กันนะครับ โดยในบทความนี้จะประกอบไปด้วย
-
Task Setting โดยเราจะมาพูดถึงตัว Sentiment Analysis กันครับว่าตัว Sentiment Analysis คืออะไร ทำไปเพื่ออะไร และเราจะต้องใช้ข้อมูลอะไรบ้างเป็น input-output
-
Getting to know Bert:เราจะมาพูดถึงเจ้าตัว Bert แบบคร่าว ๆ เอาแค่จุดประสงค์ของมันจุดเด่นของมันไม่ลงลึกถึงวิธีการคำนวณ เพื่อให้เรารู้พอที่จะใช้ Bert เป็นเท่านั้นครับ
-
Getting to know the data: เราจะมาดูว่าวันนี้เราจะใช้ datasets อะไร และต้องเตรียมตัวอะไรก่อนทำ model บ้าง
-
Getting it done:เราจะมาพูดถึงแต่ละ step ที่เราทำว่าเราทำอะไรบ้างเพื่อจุดประสงค์อะไร
เอาหละครับ เรามาเริ่มเข้าสู่ตัวบทความจริง ๆ กันดีกว่า
![]() โดยคุณ ณัฐพล มณีโชติ (เฟรม)
โดยคุณ ณัฐพล มณีโชติ (เฟรม)
นักศึกษา ป.โท จุฬาฯ ที่จะมาเรียนรู้ไปพร้อม ๆ กับคุณ
“All I know is that I know nothing” -Socrates
Task Setting
ก่อนที่เราจะมาทำตัว model เราก็ต้องจำเป็นที่จะรู้ก่อนใช่ไหมครับว่า Sentiment Analysis เนี่ย คืออะไร และ Analysis ในแง่ไหน
Sentiment Analysis
Sentiment Analysis คือ การที่เราจะนำเอาประโยคไปดูครับว่าประโยคเนี่ยมีความคิดเห็นยังไงชอบ ไม่ชอบ หรือ เฉย ๆ กับสิ่งที่เขากำลังพูดถึง ยกตัวอย่างเช่น
-
“อาหารพอกินได้นะ” =>”เฉย ๆ ”
-
“จานนี้อร่อยมากเลยนะครับ” => “ชอบ”
-
“ผมว่าอาหารต้องปรับปรุงนะ” => “ไม่ชอบ”

แล้วการที่เรามี automate tool เพื่อที่จะบอกว่าคนเขียนรู้สึกยังไงมันดีตรงไหนกันหละ ??
การที่มี automate tool เพื่อที่จะทำ Sentiment Analysis เนี่ยเป็นผลดีกับร้านค้าต่างๆ อย่างมากนะครับ ลองนึกภาพถ้าเราทำ survey ของร้านค้ามา เราก็จะได้รู้ว่าเขาพูดถึงร้านค้าโดยรวมไปในทางที่ดีหรือทางที่แย่ และเรายังสามารถขุดไปให้ลึกว่าเดิมได้ โดยอาจจะเข้าไปดูในกลุ่มที่บอกว่าแย่ ว่าร้านค้าเราควรปรับปรุงตรงไหน หรือ เข้าไปดูในกลุ่มที่บอกว่าดีเพื่อหาจุดเด่นของร้านค้าในการนำไปพัฒนาต่อก็ได้นั่นเองครับ
Data requirements
เอาหละครับในเรื่องของข้อมูลที่เราจะต้องใช้ในการ train ตัว Sentiment Analysis Model ก็ คือ ตัวประโยค กับ ความคิดเห็นของประโยคนั่นเองครับโดย input คือตัวประโยค และ output คือ ความคิดเห็นบนประโยคนั้น
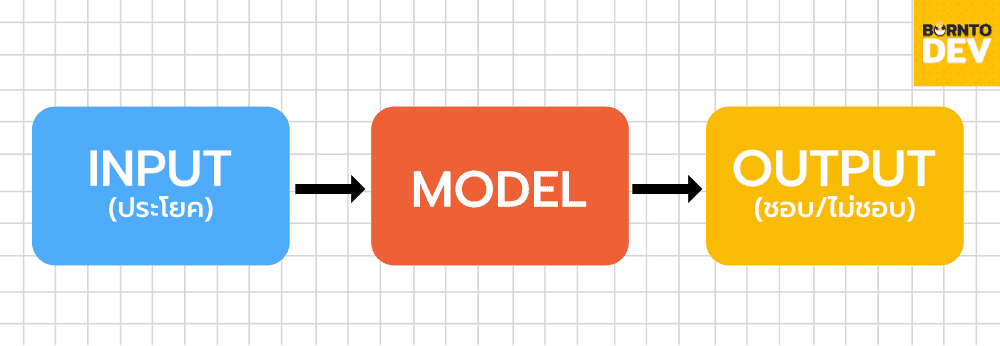
ทีนี้เมื่อเราได้รู้ว่า input output เป็นยังไงแล้ว เราก็จะไปดูกลไกหลักของ model เรากันครับ นั่นก็คือตัว Bert นั่นเอง
Getting to know Bert
ขอย้ำอีกสักทีนะครับว่าวันนี้เราจะไม่ได้มาเจาะลึกที่ตัว Bert กันแต่จะเป็นแค่การพูดถึงคร่าว ๆ ว่าใช้ทำอะไรยังไง และมีข้อดียังไงครับผม
Bert คืออะไร?
Bert นั้นพูดง่าย ๆ ก็คือการเปลี่ยนคำให้กลายเป็น vector (word embedding) โดยที่ vector เหล่านี้จะต้องสามารถที่จะ represent คุณลักษณะหรือความหมายของคำ ๆ นั้นเพื่อทำให้ model เข้าใจและนำไปใช้ต่อได้นั่นเองครับ
Bert word embedding เก็บความหมายของคำได้ยังไง?
เราจะมาพูดถึง concept หลัก ๆ ของ Bert โดยไม่ลงไปที่ math นะครับ โดยหลัก ๆ ก็คือ Bert จะถูกสอนให้เรียนการเติมคำในช่องว่าโดยใช้คำรอบ ๆ (Cloze task) เหมือนที่เราเคยทำกันตอนเด็ก ๆ ตอนที่เราเรียนภาษาอังกฤษกันนั่นหละครับถ้าจำไม่ได้ก็จะเป็นแบบในตัวอย่างด้านล่างครับ

โดยการทำ cloze task นี้เนี่ยถ้าทำได้ก็จะแสดงว่าเราเข้าใจความหมายของคำรอบ ๆ และคำที่เติมเพราะฉะนั้น word embedding ที่ออกมาจึงพอจะเข้าใจได้ว่าเป็นความหมายของคำ ๆ นั้นแล้วนั่นเองครับผม
นอกจากนี้ bert ยังทำตัว Next Sentence Prediction task หรือการทำการเดาว่าประโยคนั้นต่อกันหรือเปล่า เพื่อเป็นตัวแทนของความเข้าใจการสรุปผลของ bert อีกด้วยครับ โดยความหมายของประโยคนี้จะอยู่ใน vector ที่เรียกว่า CLS embedding เพื่อเป็นตัวแทนของประโยคอีกด้วยครับ
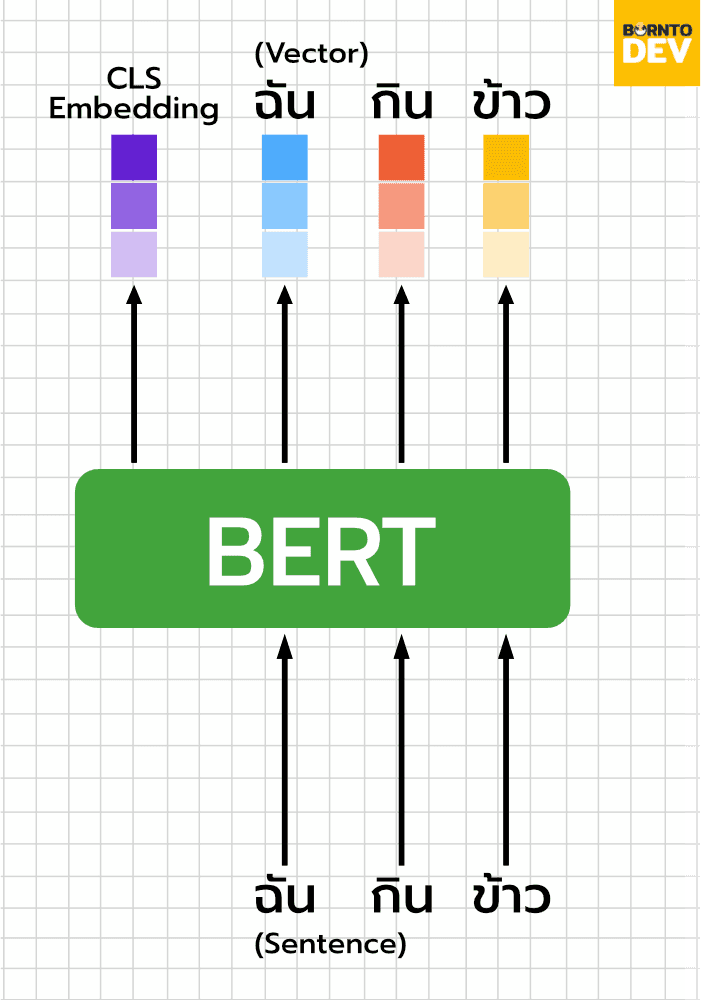
Getting to know the data
ข้อมูลที่เราจะนำมาใช้ในวันนี้คือตัว Amazon Musical Instrument dataset ครับ โดยจะประกอบไปตัว review ของ เครื่องดนตรี และ rating ของ review นั้น ๆ จากการที่เราต้องการความรู้สึกของประโยคแทนที่จะเป็น rating เราเลยจำเป็นที่จะต้องเปลี่ยน rating ให้กลายเป็นความรู้สึกก่อนครับ โดยถ้า rating มากกว่าสามเราจะคิดว่าเขาชอบ rating น้อยกว่า 3 เราจะคิดว่าเขาไม่ชอบและ rating เท่ากับสามคือเฉย ๆ นั่นเองครับ
Getting it done
ท้ายที่สุดนะครับผมจะมาพูดกระบวนการต่าง ๆ ในการทำโดยนำเสนอพร้อมกับโค้ดให้ทุก ๆ ท่านหวังว่าทุก ๆ ท่านจะนำไปปรับใช้ได้นะครับ โดยผมจะอธิบายแค่โค้ดส่วนใหญ่ ๆ นะครับผม
Import and setting module
import pandas as pd
import os
import pickle as pkl
import numpy as np
import gzip
import tensorflow as tf
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.utils import to_categorical
from tokenizers import BertWordPieceTokenizer
from transformers import BertTokenizer, TFBertModel, BertConfig
encoder = TFBertModel.from_pretrained("bert-base-uncased")
ในโค้ดส่วนนี้เราทำการ import modules ที่เราใช้ทั้งหมดมาครับ แล้วก็ทำการสร้างตัวแปรสำหรับ bert word embedding layer ของเราครับผม
import data and preprocessing
def parse(path):
g = gzip.open(path, 'rb')
for l in g:
yield eval(l)
def getDF(path):
i = 0
df = {}
for d in parse(path):
df[i] = d
i += 1
return pd.DataFrame.from_dict(df, orient='index')
df = getDF('/content/reviews_Musical_Instruments_5.json.gz')
df = df[['reviewText','overall']]
def splitSentiment(x):
if x<3:
return 0
elif x==3:
return 1
elif x>3:
return 2
good = df[df['overall']>=4]
neutral = df[df['overall']==3]
bad = df[df['overall']<=2]
_min = min(good.shape[0],neutral.shape[0],bad.shape[0])
good = good.sample(n=_min)
neutral = neutral.sample(n=_min)
bad = bad.sample(n=_min)
df = pd.concat([good,neutral,bad])
df = df.sample(frac=1)
encoder = TFBertModel.from_pretrained("bert-base-uncased")
ต่อมาเราก็ทำการ import data และจัดให้อยู่ในรูปที่ง่ายต่อการทำงานครับ และเราก็ทำการเปลี่ยน rating ให้กลายเป็น sentiment แบบที่เคยได้เล่าสู่กันฟังตอนแรกด้วยครับ
Data sampling & splitting
ก่อนจะเริ่มเข้าสู่ตัว model เราก็ต้องทำการ down sampling ข้อมูลของในแต่ละคลาส (ประโยคที่ชอบ/ไม่ชอบ/เฉย ๆ ) ของเราให้เท่ากันก่อนครับ เนื่องจากข้อมูลที่มากไปในคลาสใดคลาสหนึ่งอาจทำให้ model ของเราเกิดความเข้าใจผิดและทำนายเป็น class นั้นเยอะ ๆ ก็เป็นได้ ทำให้การที่มันเก่งไม่ใช่เพราะเข้าใจประโยคแต่เป็นเพราะ class นั้นมันมีเยอะสุดเลยเดาเป็น class นั้นไป
ยกตัวอย่างเช่นผมจะสร้างโมเดลที่เอาไว้ทายว่าหวยเลขนี้โดนกินหรือเปล่า model นั้นก็สามารถเดาได้ง่าย ๆ เลยว่าโดนกินแน่ ๆ เนื่องจากจำนวนหวยที่ถูกนั้นมีน้อยกว่าหวยที่โดนกินมาก ๆ ทำให้แม้ว่า model จะเดาตอบแต่โดนกินก็ยังได้ accuracy สูงอยู่นั้นเองครับ
good = df[df['overall']>=4]
neutral = df[df['overall']==3]
bad = df[df['overall']<=2]
_min = min(good.shape[0],neutral.shape[0],bad.shape[0])
good = good.sample(n=_min)
neutral = neutral.sample(n=_min)
bad = bad.sample(n=_min)
df = pd.concat([good,neutral,bad])
df = df.sample(frac=1)
encoder = TFBertModel.from_pretrained("bert-base-uncased")
def StratifiedSplit(dat,label_name,split_ratio):
total_row=dat.count()[0]
labels=dat[label_name].unique()
ratio_dict={}
for i in labels:
ratio_dict[i]=dat.where(dat[label_name]==i).dropna().count()[0]/total_row
num_sample=int(total_row*split_ratio)
test_df=pd.DataFrame(columns=dat.columns)
train_df=pd.DataFrame(columns=dat.columns)
for i in labels:
num_sample_label =int(num_sample*ratio_dict[i])
dat_sm=dat.where(dat[label_name]==i).dropna()
dat_sm=dat_sm.sample(frac=1)
msk = np.random.rand(dat_sm.count()[0]) <
(num_sample_label/dat_sm.count()[0])
test_df=test_df.append(dat_sm[msk])
train_df=train_df.append(dat_sm[~msk])
return (train_df, test_df)
หลังจากทำการ down sampling แล้ว เราจะแบ่งข้อมูล เป็นสามชุด คือ train, validation แล้วก็ test ก่อนครับ โดยการแบ่งข้อมูลสำหรับ task นี้เนี่ยเราจะใช้การแบ่งที่เรียกว่า stratified splitting ซึ่งจะทำให้ข้อมูลที่ sample ออกมามีสัดส่วนของ class ที่เท่ากับอันเดิมที่เป็น source data ครับ การทำแบบนี้จะเป็นการรักษาสัดส่วนที่เราทำการ down sampling เอาไว้ให้เท่าเดิมไม่เสียความเท่าเทียมของข้อมูลที่เราทำไว้ครับ
word preprocessing
การเตรียมคำไว้สำหรับแปลงเป็น vector นั้นเราจะต้องแปลงคำให้เป็น index ของคำแล้วเติมสิ่งที่ Bert จำเป็นต้องใช้เข้าไปครับเช่น CLS token, attention mask ต่าง ๆ ครับ ในส่วนนี้เราสามารถให้ module haggingface จัดการให้เราได้เลยครับผม
### LOAD BERT TOKENIZERS ###
# Save the slow pretrained tokenizer
slow_tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
save_path = "bert_base_uncased/"
if not os.path.exists(save_path):
os.makedirs(save_path)
slow_tokenizer.save_pretrained(save_path)
# Load the fast tokenizer from saved file
tokenizer = BertWordPieceTokenizer("bert_base_uncased/vocab.txt", lowercase=True)
x_ids_tr=[tokenizer.encode(i).ids for i in train_["reviewText"]]
x_ids_tr=pad_sequences(x_ids_tr,maxlen=max_seq,padding="post")
x_msk_tr=[tokenizer.encode(i).attention_mask for i in train_["reviewText"]]
x_msk_tr=pad_sequences(x_msk_tr,maxlen=max_seq,padding="post")
y_tr=to_categorical(train_["overall"].values)
#Bert input_ids = tf.keras.layers.Input(shape=(max_seq,), dtype=tf.int32) attn_mask = tf.keras.layers.Input(shape=(max_seq,), dtype=tf.int32) ## CLS=1 All word emb=0 wrd_embedding = encoder(input_ids, attention_mask=attn_mask)[1] drop=tf.keras.layers.Dropout(0.8)(wrd_embedding) res=tf.keras.layers.Dense(8,activation="relu")(drop) res2=tf.keras.layers.Dense(8,activation="relu")(res) ### Result Dense res3=tf.keras.layers.Dense(3,activation="softmax")(res2) model=tf.keras.Model(inputs=[input_ids,attn_mask] ,outputs=res3)
Model
ในส่วนของ ตัว model เนี่ยเราจะเอา bert pretrained layer มา fine tune(fine tune คือการ train ตัว word embedding ให้เปลี่ยนแปลงไปเล็กน้อยเพื่อให้เหมาะกับ task เฉพาะทางที่ทำ) ให้เข้ากับ task ของเราครับโดยเราจะเอาตัว CLS ที่เป็นตัวแทนของประโยคไปผ่าน Muti layer perceptrons สองชั้นและชั้นสุดท้ายของ Muti layer perceptrons จะมี softmax activation function ซึ่งเป็นฟังก์ชันที่ทำให้ค่าในแต่ละมิติของ vector บวกกันได้ 1 ครับเพื่อให้ vector ที่แทน probability disturbution ของ แต่ละ class(ชอบ, ไม่ชอบ, เฉย ๆ ) ที่โมเดลทายนั่นเองครับ
ในส่วนของ model นั้นเราจะใช้ตัว tensorflow จัดการเรื่อง loss function และ backpropagation ต่าง ๆ ให้ครับ
“`โค้ดสำหรับกำหนด loss function
model.compile(optimizer=tf.keras.optimizers.Adam(0.001),loss=tf.keras.loss es.CategoricalCrossentropy(),metrics=["accuracy"])
“`โค้ดสำหรับ train model
history=model.fit(x=[x_ids_tr,x_msk_tr],y=y_tr,epochs=10,validation_data=( [x_ids_t,x_msk_t],y_t),verbose=1,batch_size=8,callbacks=callbacks)
สรุป
เท่านี้คุณก็ทำ Sentiment analysis ด้วย Bert ของคุณเองได้แล้วหละครับ ขอบคุณที่เข้ามาอ่านจนถึงจุดนี้นะครับ หากมีข้อผิดพลาดประการใดขออภัยมา ณ ที่นี้ด้วยนะครับผม
Code เต็ม: https://github.com/Natthapolmnc/SentimentAnalysis
หากคุณสนใจพัฒนา สตาร์ทอัพ แอปพลิเคชัน
และ เทคโนโลยีของตัวเอง ?
อย่ารอช้า ! เรียนรู้ทักษะด้านดิจิทัลเพื่ออัพเกรดความสามารถของคุณ
เริ่มตั้งแต่พื้นฐาน พร้อมปฏิบัติจริงในรูปแบบหลักสูตรออนไลน์วันนี้
-
Sale!

-
Sale!
-
Sale!
-
Sale!








