แล้ว OCR นำไปใช้กับอะไรได้บ้าง
- ภาพถ่ายป้ายถนนและผลิตภัณฑ์
- เอกสาร
- ใบแจ้งหนี้
- รายงานทางการเงิน
- บทความและอื่นๆ
ทำความรู้จักกับบริการ Azure Computer Vision
1. OCR API: เป็น API ที่ใช้สำหรับอ่านข้อความจำนวนน้อยๆถึงปานกลางจากรูปภาพ
สามารถอ่านข้อความได้หลายภาษาผลลัพธ์จะถูกส่งกลับทันทีจากการเรียกใช้ฟังก์ชันเดียว
2. Read API: เป็น API ที่ใช้สำหรับอ่านข้อความตั้งแต่ขนาดเล็กถึงขนาดใหญ่จากรูปภาพและเอกสาร PDF โดย API นี้ใช้โมเดลที่ใหม่กว่า OCR API เลยทำให้มีความแม่นยำมากขึ้น
Read API สามารถอ่านข้อความที่พิมพ์ออกมาได้หลายภาษา และข้อความที่เขียนด้วยลายมือเป็นภาษาอังกฤษการเรียกใช้ฟังก์ชันเริ่มต้นจะส่งคืน ID การดำเนินการแบบอะซิงโครนัส ซึ่งต้องใช้ในการเรียกครั้งถัดไปเพื่อดึงผลลัพธ์
มาเริ่มสร้างโปรแกรมอ่านข้อความในภาพกันเลย
1. หากยังไม่ได้สมัคร Azure สามารถลงทะเบียนเพื่อทดลองใช้งานฟรีได้ที่ https://azure.microsoft.com/free/
2. เมื่อมีบัญชี Azure แล้วให้ไปที่ https://portal.azure.com และลงชื่อเข้าใช้ด้วยบัญชี Microsoft ที่ได้สมัครใช้งาน Azure ไว้ในเบื้องต้น และเลือกปุ่ม + Create a resource
3. ค้นหา Cognitive Services แล้วกดสร้างบริการได้เลย
4. โดยการสร้างบริการ Cognitive Service จะตั้งค่าดังนี้:
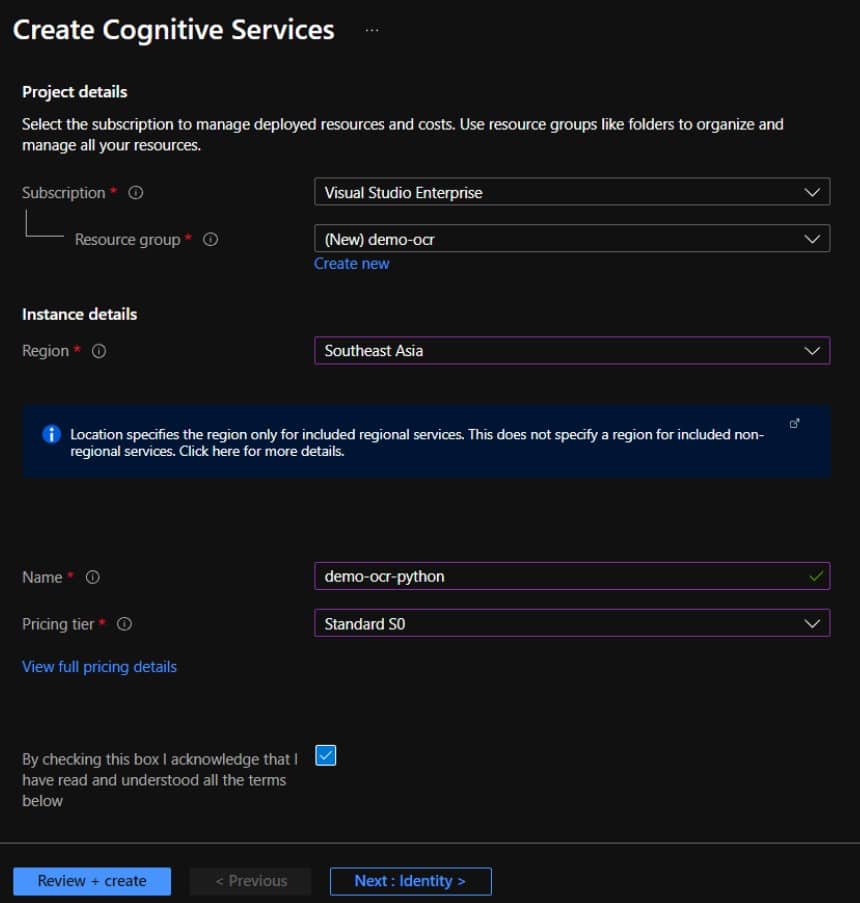
- Subscription : การสมัครสมาชิก Azure ของคุณ
- Resource group: เลือกหรือสร้างกลุ่มทรัพยากร
- Region: เลือกภูมิภาคที่มีอยู่
- Name: ให้ตั้งชื่อที่ไม่ซ้ำกับคนอื่น
- Pricing tier: ระดับราคามาตรฐานเลือก S0
โดยราคาของบริการนี้จะเป็นดังนี้
- 0-1M transactions — $1 ต่อ1,000 transactions
- 1M-10M transactions — $0.65 ต่อ 1,000 transactions
- 10M-100M transactions — $0.60 ต่อ 1,000 transactions
- 100M+ transactions — $0.40 ต่อ 1,000 transactions
5. คลิกเลือกยอมรับและรับทราบ terms ของบริการ หลังจากนั้นสามารถกดปุ่ม Review + Create และเมื่อ Validation Passed แล้วสามารถกด Create ได้เลย
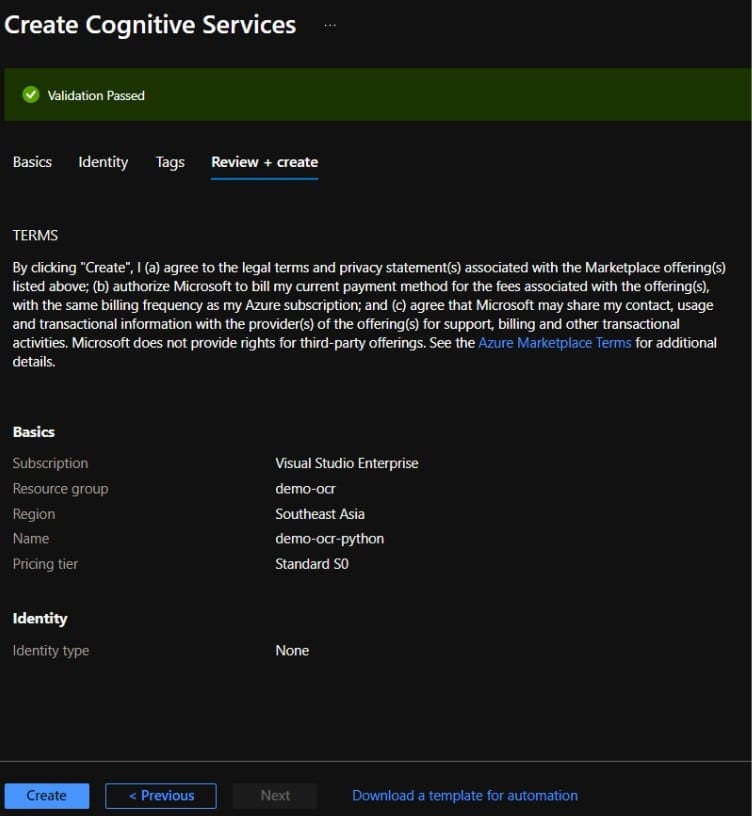
6. เมื่อบริการสร้างเสร็จสามารถกดปุ่ม Go to resource ได้เลย
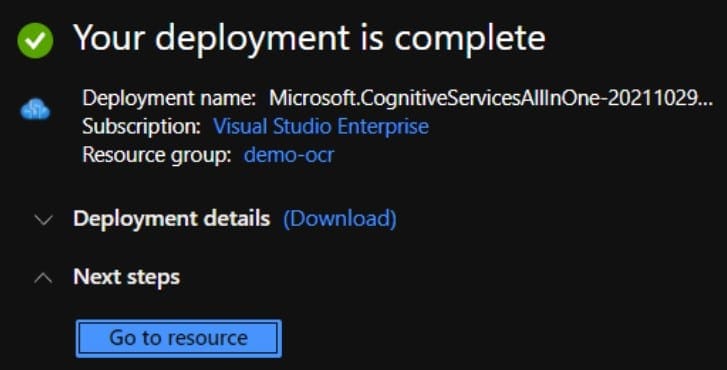
7. หลังจากนั้นจะมาพบกับหน้า Overview ให้ไปยัง Keys and Endpoint
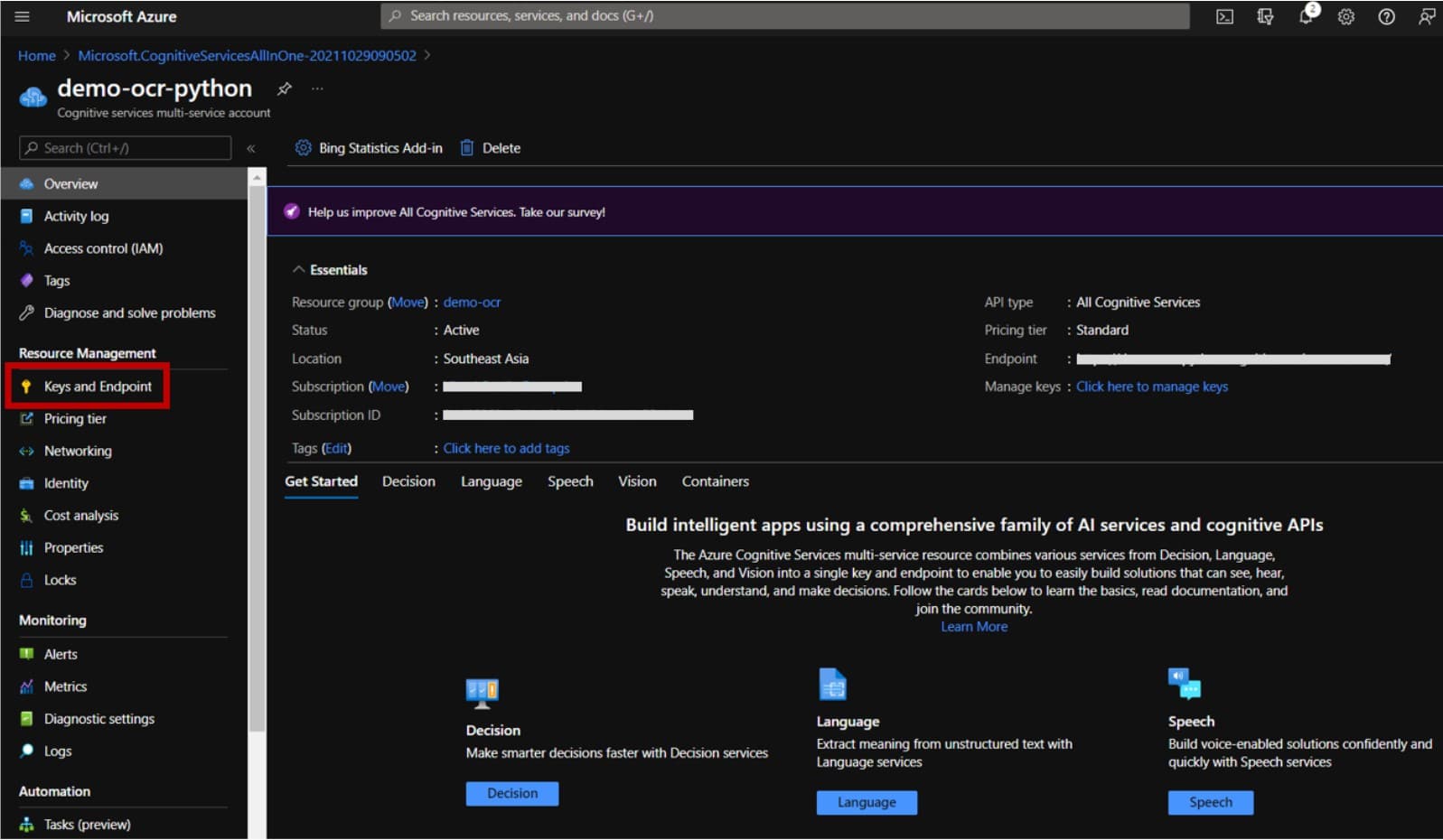
8. ให้เราทำการคัดลอกค่า KEY1 หรือ KEY2 ก็ได้และ Endpoint ด้วยนะครับ
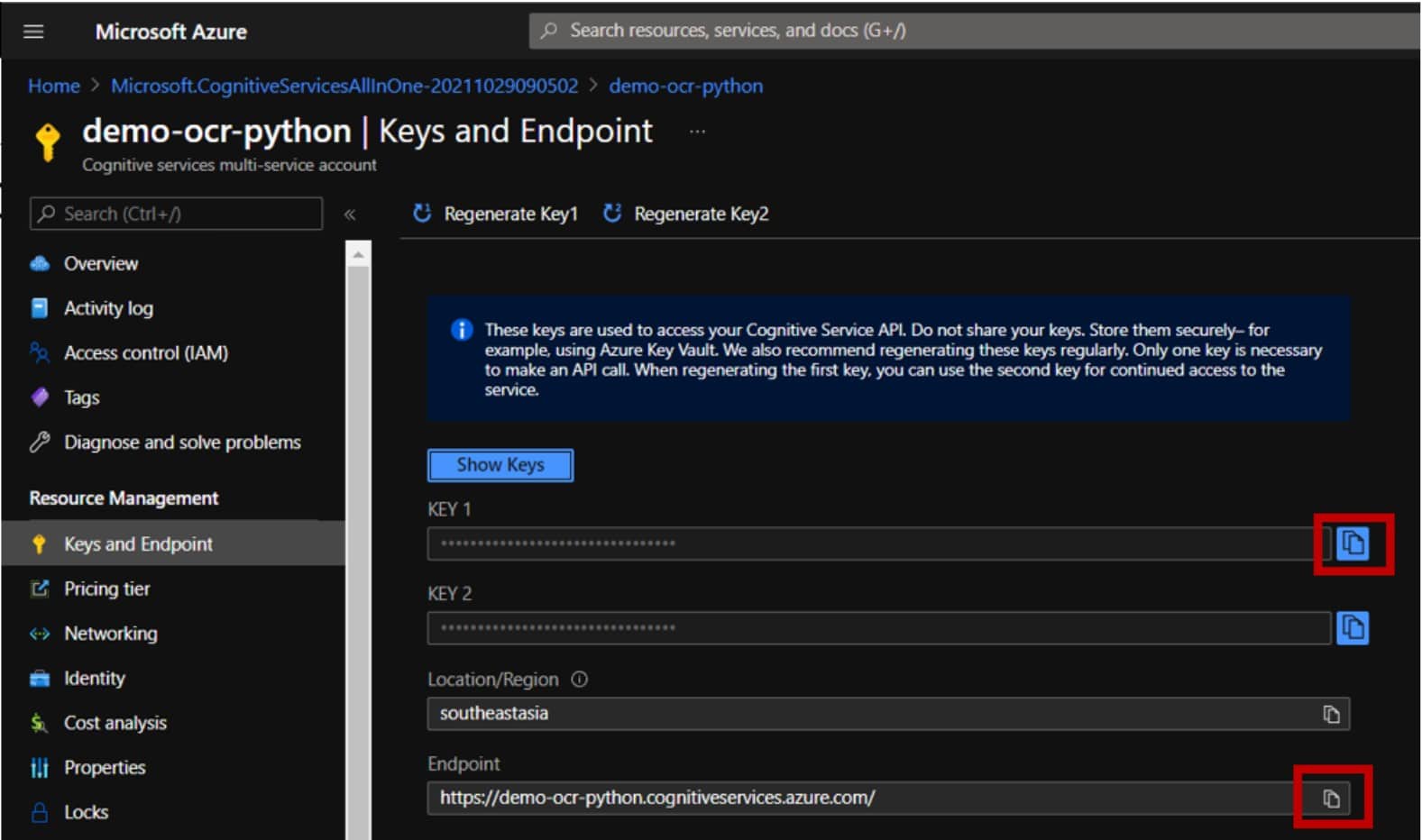
9. ให้ทำการ git clone https://github.com/aeff60/OCR-Azure-sample.git แล้ว cd เข้าไปยัง directory ของโปรเจค
10. สร้าง python environment ด้วยคำสั่ง virtualenv ตามด้วยชื่อenv
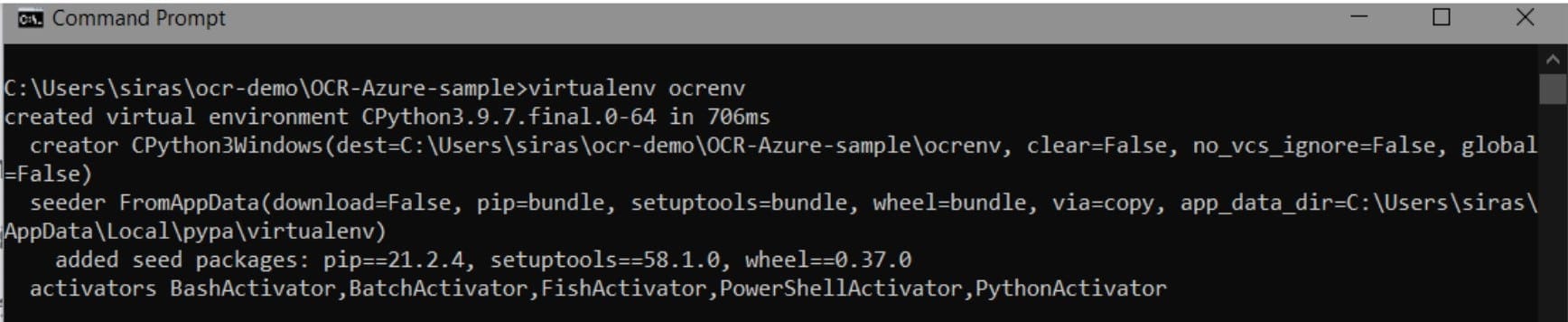
11. ทำการ activate python environment โดยการใช้คำสั่ง ชื่อenv\scripts\activate

12. ทำการติดตั้งไลบรารีจากไฟล์ requirements.txt ด้วยคำสั่ง pip install -r requirements.txt

13. แล้วเปิด Visual Studio Code จากใน directory นี้ด้วยคำสั่ง code .

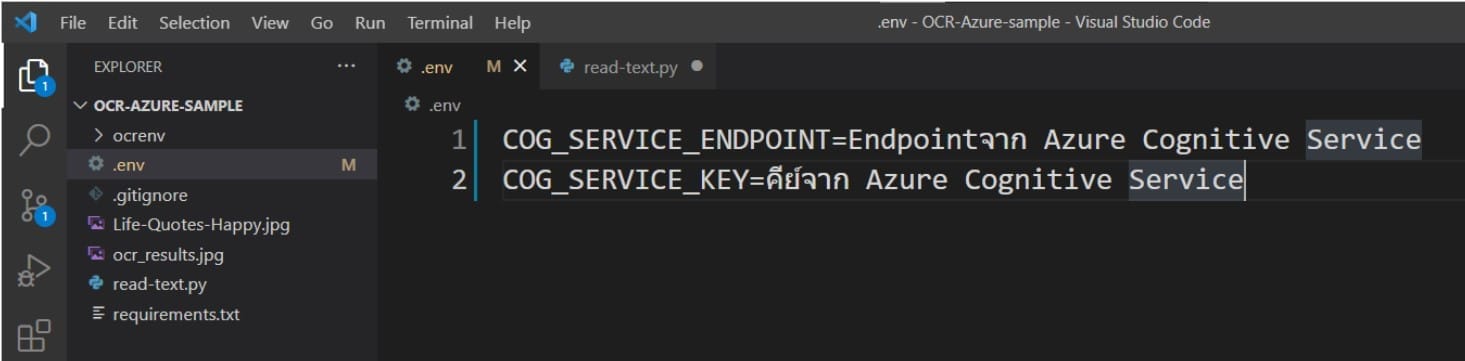
14. นำ KEY และ Endpoint จาก Azure มาใส่ในไฟล์ .env
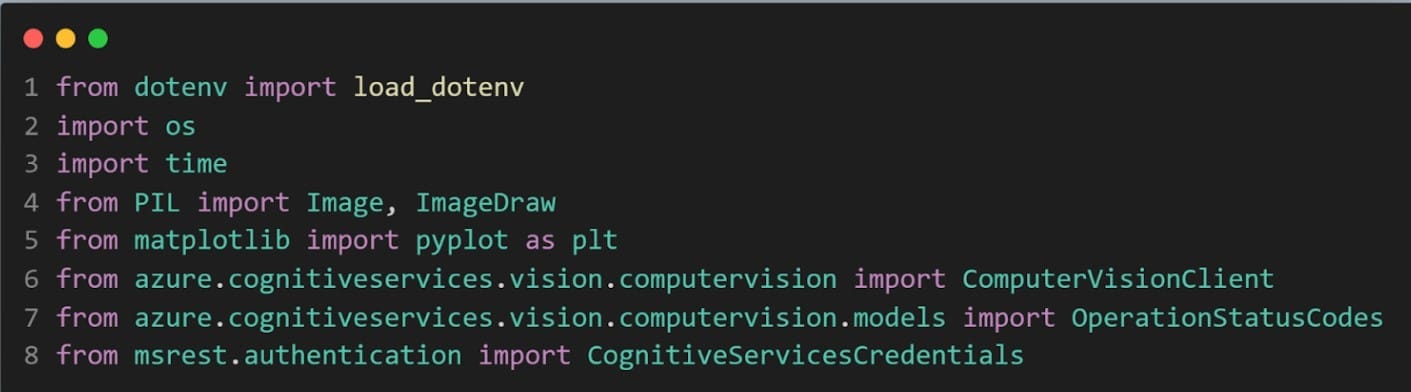
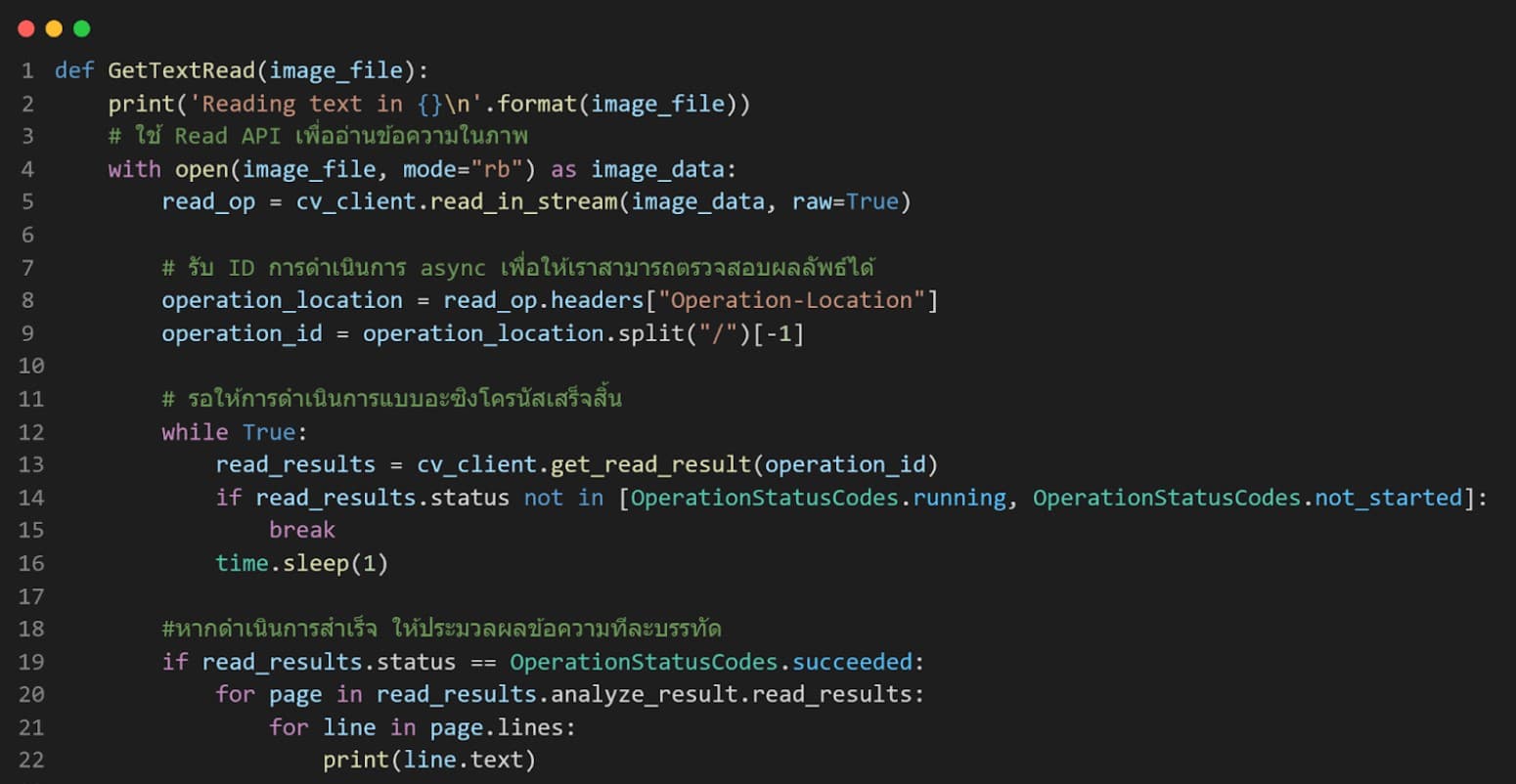
15. หลังจากนั้น ไปยังไฟล์ read-text.py โดยในส่วนแรกจะเป็นการเรียกใช้งานไลบรารีที่เกี่ยวข้อง
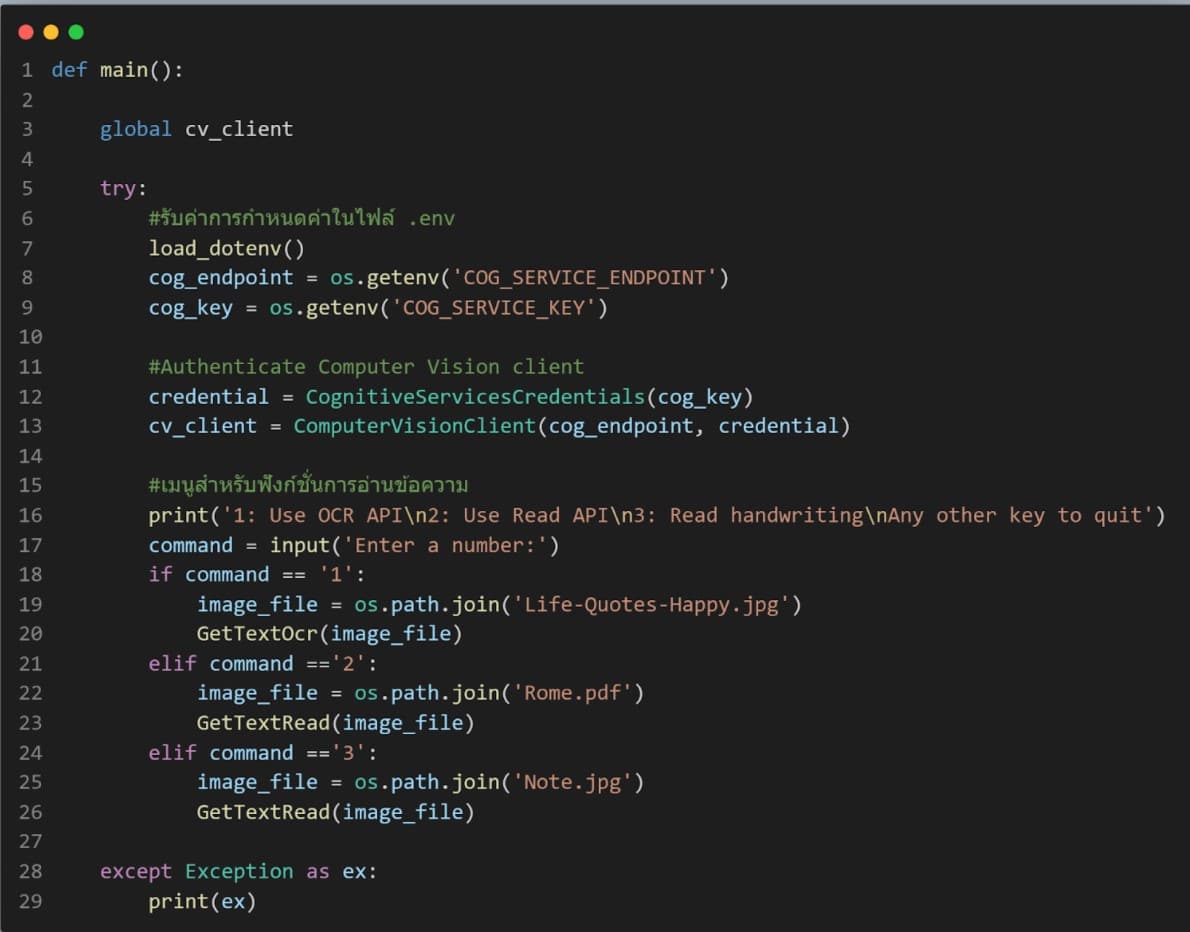
16. ส่วนที่สองจะเป็นการรับค่าจากไฟล์ .env เพื่อ Authenticate บริการ Azure Computer Vision และเนื่องจากในโค้ดเราได้มีการใช้งาน API ทั้งแบบ OCR API และ Read API จึงได้สร้างเมนูไว้ 3 เมนู
- เมนูที่ 1 จะเป็นการอ่านข้อความจากภาพโดยใช้ OCR API โดยจะอ่านข้อความในภาพที่ข้อความจำนวนไม่เยอะมากนัก
- เมนูที่ 2 จะเป็นการอ่านข้อความในไฟล์ PDF โดยใช้ Read API โดย API นี้จะอ่านข้อความที่มีปริมาณเยอะๆได้
- เมนูที่ 3 จะเป็นการอ่านข้อความที่เป็นตัวเขียนด้วยลายมือ โดยใช้ Read API ซึ่ง API นี้รองรับข้อความที่เป็นตัวเขียนด้วยลายมือ
17. ซึ่งในฟังก์ชันของการอ่านข้อความด้วย OCR API จะประกอบไปด้วยการเตรียมรูปภาพที่ต้องการอ่านข้อความในภาพ การเรียกใช้งาน OCR API การประมวลผลข้อความทีละบรรทัดเพื่อแสดงตำแหน่งของข้อความในภาพ หลังจากนั้นทำการตีกรอบข้อความที่อยู่ในภาพและบันทึกภาพที่ได้ตีกรอบข้อความไว้
18. ภาพต้นแบบที่ใช้ในการทดสอบ
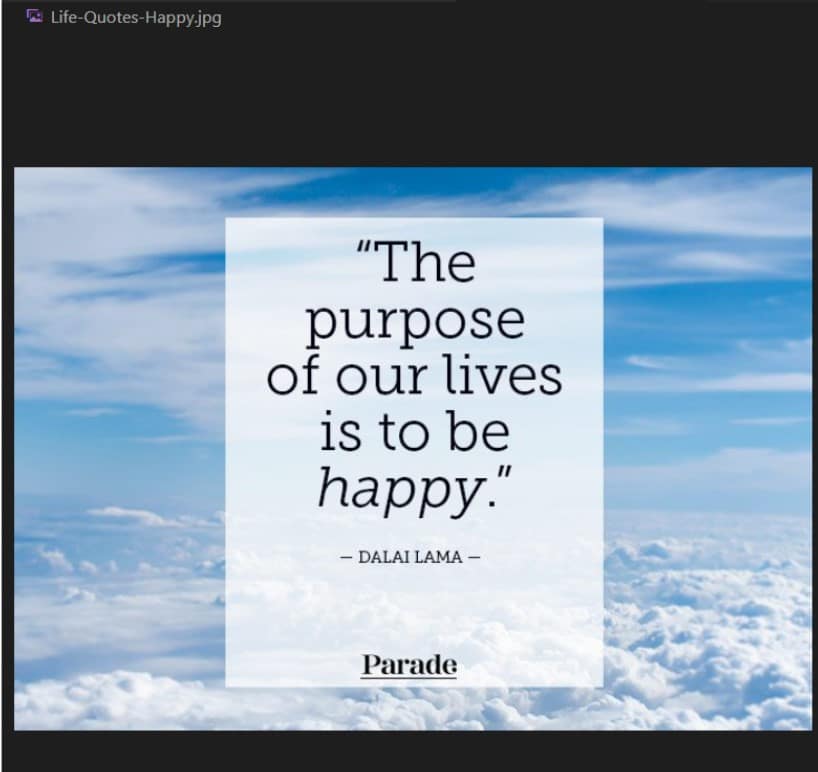
19. ใช้คำสั่ง python แล้วตามด้วยชื่อไฟล์ เพื่อทำการรันโปรแกรม หลังจากนั้นใส่เลขเมนูที่ต้องการใช้งาน โดยตัวอย่างแรกเราจะเลือกใช้ OCR API ในการอ่านข้อความในภาพ เมื่อรันเสร็จ API จะทำการอ่านข้อความในภาพและแสดงข้อความที่อ่านได้ผ่านหน้าต่าง command prompt
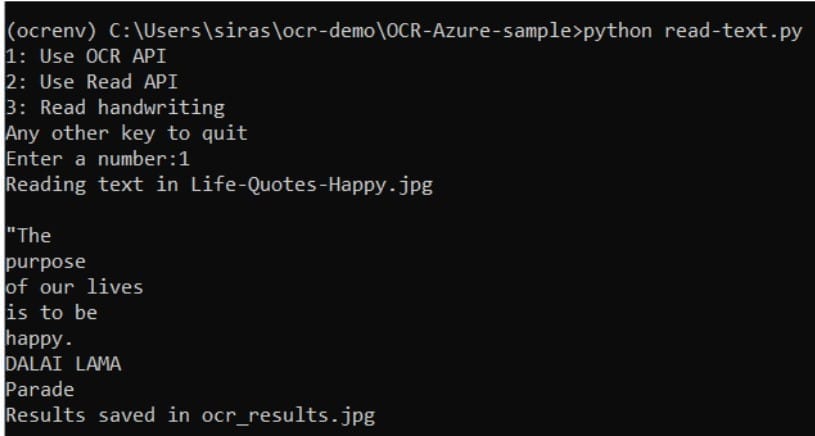
20. และจะทำการตีกรอบข้อความในภาพ เพื่อให้เราสามารถดูได้ว่า API อ่านข้อความได้ทั้งหมดไหม
 21. ต่อไปในฟังก์ชันอ่านข้อความในภาพหรือไฟล์ PDF ด้วย Read API โดย API นี้จะทำงานแบบ asynchronous จึงจำเป็นต้องรับไอดี เพื่อให้สามารถตรวจสอบผลลัพธ์ได้ หลังจากนั้นต้องรอการดำเนินการแบบ asynchronous เสร็จสิ้นแล้ว API จะทำการประมวลผลข้อความทีละบรรทัดและแสดงออกมาผ่าน command prompt
21. ต่อไปในฟังก์ชันอ่านข้อความในภาพหรือไฟล์ PDF ด้วย Read API โดย API นี้จะทำงานแบบ asynchronous จึงจำเป็นต้องรับไอดี เพื่อให้สามารถตรวจสอบผลลัพธ์ได้ หลังจากนั้นต้องรอการดำเนินการแบบ asynchronous เสร็จสิ้นแล้ว API จะทำการประมวลผลข้อความทีละบรรทัดและแสดงออกมาผ่าน command prompt
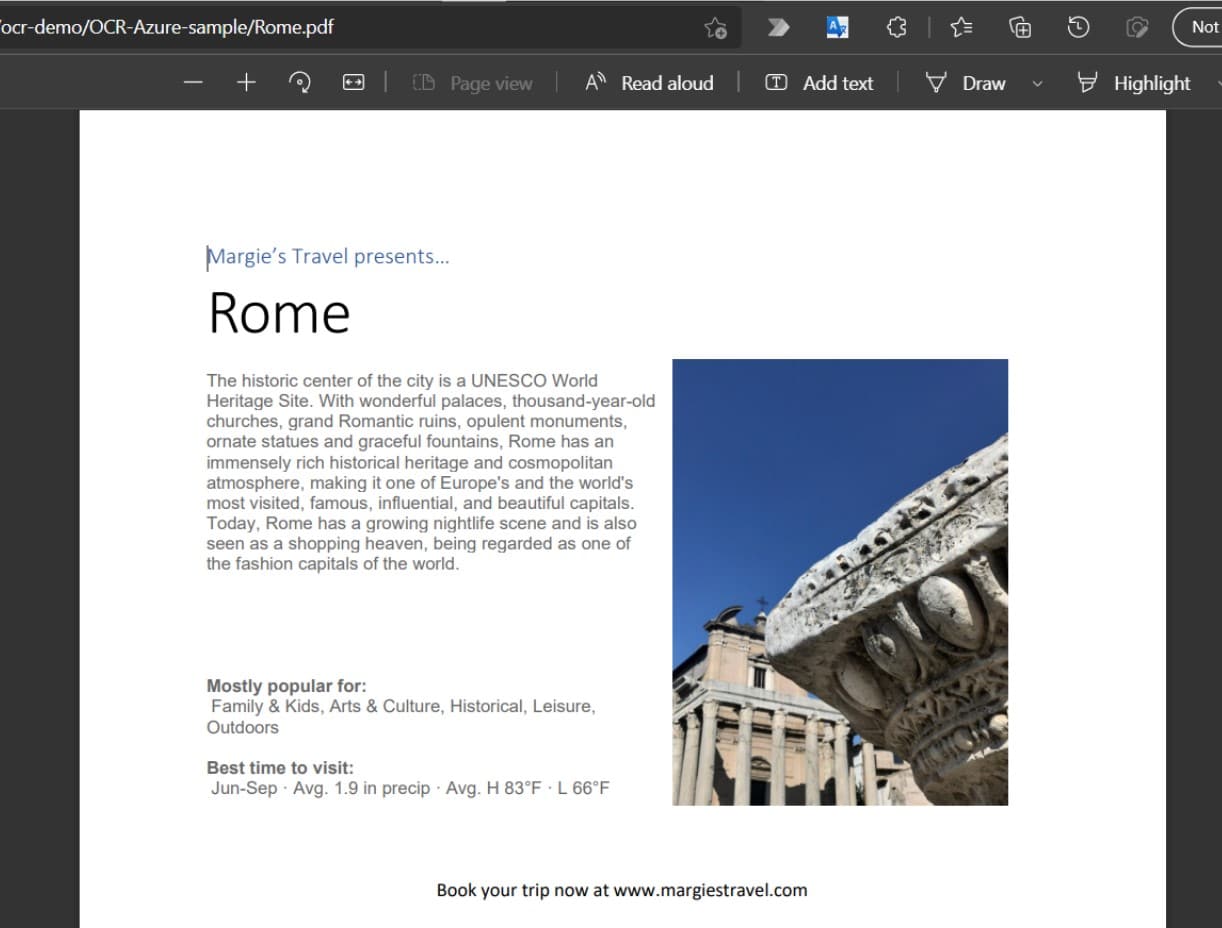
22. ตัวอย่างไฟล์ PDF ต้นฉบับ
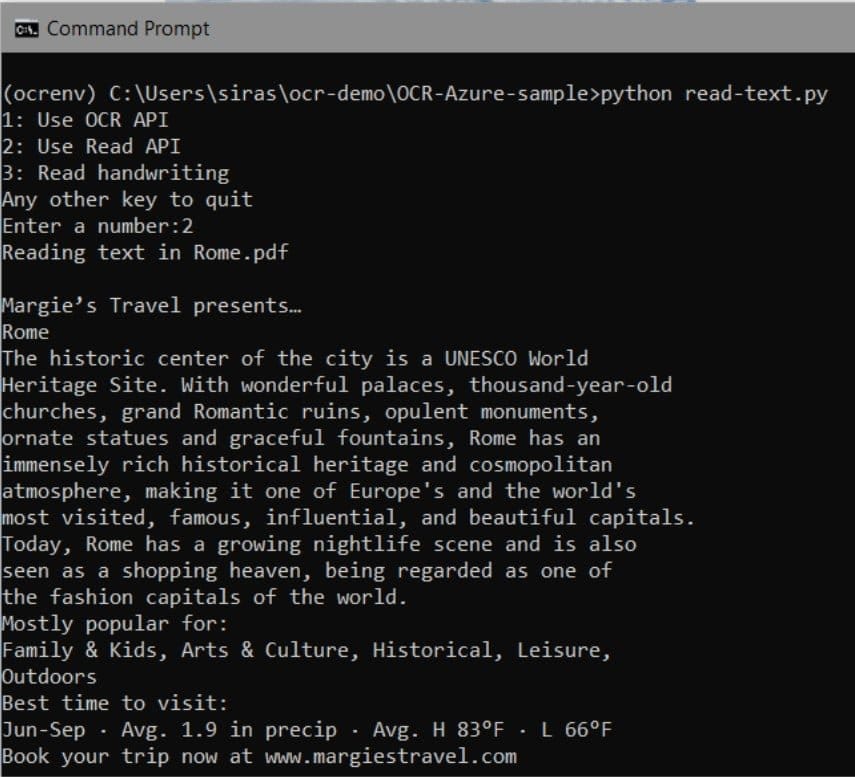
23. ให้เราทำการรันโปรแกรมอีกครั้ง แล้วเลือกเมนูที่ 2 จะเห็นได้ว่าโปรแกรมจะอ่านข้อความและแสดงข้อความที่อ่านได้ออกมาผ่าน command prompt
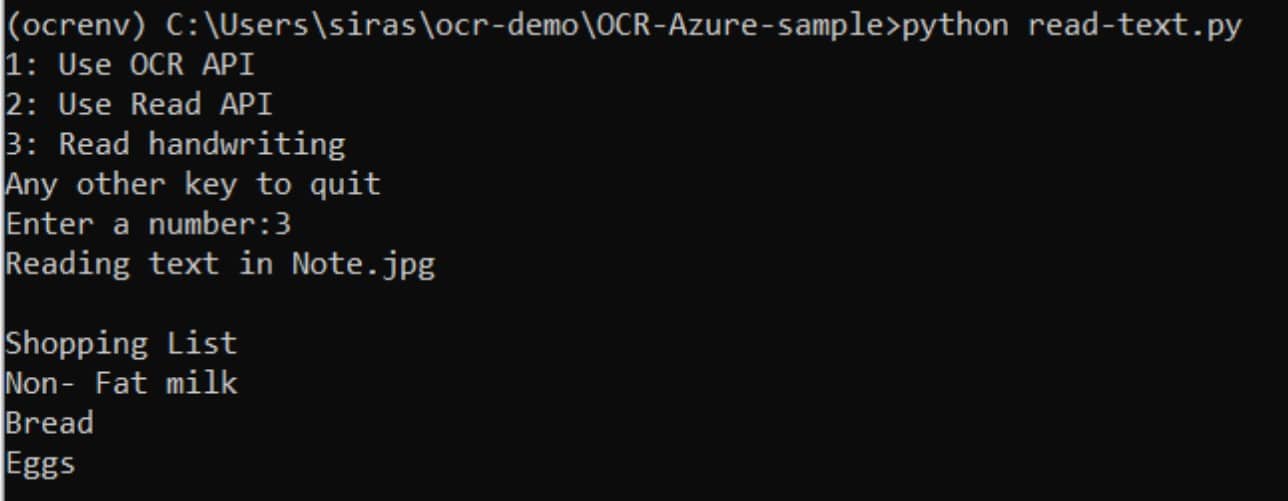
24. ต่อไปเราจะมาลองอ่านข้อความจากภาพที่เขียนด้วยลายมือกันครับ
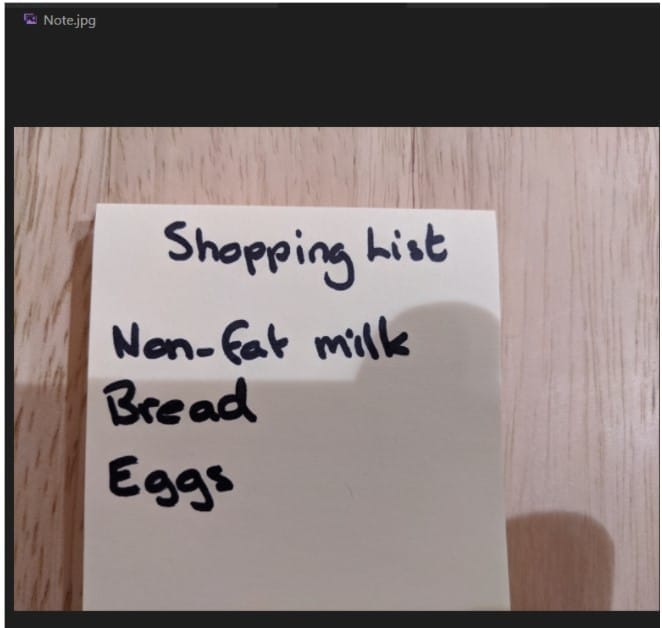
25. เนื่องจากในโค้ดส่วนเมนูเรานำ path ของภาพใส่ไว้เรียบร้อยแล้วสามารถรันโปรแกรมและเลือกเมนูที่ 3 ได้เลยครับ API จะอ่านข้อความจากในภาพออกมาและแสดงผ่านทาง command prompt
โดย OCR API และ Read API สามารถใช้งานกับภาษาอื่นๆ ได้อีกด้วยสามารถอ่านรายละเอียดภาษาที่รองรับได้ที่ Language support – Computer Vision – Azure Cognitive Services | Microsoft Docs


 เขียนโดย
เขียนโดย






